When you start preparing for System Design interviews, it is tempting to jump straight into designing complex architectures like newsfeeds, chat apps, or search engines. A great designer masters the System Design fundamentals. These foundational concepts shape every distributed system, regardless of its scale or purpose.
This guide explores these fundamentals step by step. We will cover system components, data flow, architecture choices, caching, indexing, and scalability. You will also see how these principles apply to real-world examples.

Now, let’s start with understanding what System Design is.

Understanding System Design
System Design is the process of defining the architecture, components, interfaces, and data flow of a system to meet specific requirements. The goal is to design a solution that can handle millions of users, recover from failures, and deliver results within milliseconds.
System Design fundamentals provide a framework to ensure low latency and reliability under load while making your system scalable and fault-tolerant. This helps you answer important questions about handling high traffic or storing data efficiently. In interviews, this understanding helps you explain the reasoning behind your architectural decisions.
To master these concepts, you must first understand the primary objectives that drive every architectural decision.
Key goals of System Design
Every System Design, from a social media platform to a typeahead system, aims to balance three critical goals. These pillars often compete with one another, making trade-offs central to good design decisions.
- Scalability: Can your system handle increasing traffic by adding resources?
- Reliability: Does your system recover gracefully from failures?
- Performance: Does it meet latency and throughput requirements?
Achieving all three simultaneously is difficult. For example, increasing reliability through data replication might introduce latency, which impacts performance. Understanding these tensions is the first step in gathering requirements.
Functional vs. non-functional requirements
When approaching a design problem, always start by clarifying requirements. This step defines the system’s scope and constraints. It ensures you solve the right problem before drawing a single box.
Functional requirements describe what the system does from a user’s perspective. These are the core features, such as “Users can post photos” or “Search suggestions update as you type.” They define the business logic and the primary interactions within the application.
Non-functional requirements define how the system performs its duties. These constraints often dictate the architecture more than the features themselves. Common metrics include keeping latency under 100 ms, ensuring 99.99% uptime, or handling 1 million requests per second.
A great System Design balances both functional and non-functional requirements. For instance, some System Designs must deliver results in under 100 milliseconds regardless of traffic spikes. Once requirements are set, you can select the building blocks.
Core components of System Design
Every large-scale system is composed of several key components that work together to process requests, store data, and ensure performance. Understanding the specific role of each component allows you to compose them into a cohesive architecture.

- Client: The user-facing interface, like a web or mobile app, initiates requests.
- API gateway: The API gateway is the entry point for the backend. It manages incoming requests, handles authentication and authorization (AuthN/AuthZ), enforces rate limiting, and routes traffic to the correct services.
- Application servers: These servers contain the main business logic. In modern systems, they are often stateless, which makes them easy to scale horizontally.
- Databases: Databases store persistent data. Choices range from relational databases such as MySQL or PostgreSQL for ACID compliance to NoSQL databases such as MongoDB or Cassandra for flexible schemas and high write throughput.
- Cache: Caches provide fast data access by storing frequently used results in memory with tools like Redis or Memcached. They are essential for reducing latency and database load.
- Message queues: Queues like Kafka or RabbitMQ handle asynchronous communication and load buffering. They decouple services, allowing them to run tasks such as email notifications or video encoding in the background.
- Load balancer: This component distributes traffic evenly across servers to prevent any single node from becoming a bottleneck.
Together, these components create the blueprint for modern distributed systems. The static blueprint is only half the story. You must also understand how data moves through it.
Data flow in a distributed system
The following steps describe what typically happens when a request enters a system. This flow is crucial for System Design. Each keystroke can be a mini-request that is routed, cached, and served with minimal latency.
The user sends a request (e.g., typing a search term or posting a message). The load balancer routes the request to an available server based on a specific algorithm. The application server then processes the logic. It first performs a cache lookup to reduce database load. The database query occurs only if the cache misses. The system then updates the cache for future requests. The response is sent back to the client.
Understanding this flow helps you identify bottlenecks. To solve those bottlenecks, you apply specific architectural patterns.
Architecture patterns
Several architectural patterns form the basis of scalable systems. Choosing the right pattern depends on your team size, scalability needs, and the domain’s complexity.

- Monolithic architecture: All components, including the frontend, backend, and database access, are packaged together in a single codebase. This approach is simple to build and deploy, making it suitable for small teams or early prototypes. It becomes hard to scale and maintain as the code grows.
- Microservices architecture: Each feature runs as an independent service, communicating via APIs, often using lightweight protocols such as HTTP/REST or gRPC. This makes it easier to scale individual parts and allows teams to work autonomously. It requires strong monitoring, orchestration, and handling of distributed failures.
- Event-driven architecture: Components communicate asynchronously through message queues or event streams. This decouples services, meaning the sender does not need to wait for the receiver to process the message. It is widely used in real-time systems like chat or notification System Design pipelines.
- Client-server architecture: This is a classic pattern where clients request resources from centralized servers. While simple, it still forms the foundation of most modern distributed systems and is often wrapped inside more complex patterns.
Once you have an architecture, the next challenge is handling growth.
Vertical and horizontal scalability
Scalability determines how your system grows to handle more users or data. It is about the capability to expand capacity without redesigning the system.
Vertical scaling, or scaling up, involves increasing the resources, such as CPU or RAM, of a single server. It is easier to implement because it does not require code changes. However, it is limited by hardware capacity and introduces a single point of failure.
Horizontal scaling, or scaling out, involves adding more servers to distribute the load. This supports massive growth and offers better fault tolerance. However, it introduces complexity in data consistency, management, and inter-service communication.
To effectively manage a horizontally scaled system, you need a mechanism to distribute traffic.
Load balancing and traffic management
When requests flood your system, you need a way to distribute them efficiently. Load balancers sit between clients and servers or between services to ensure no single server is overwhelmed. Some common load balancing algorithms include:
- Round Robin: Simple rotation of requests across servers.
- Least Connections: Directs traffic to the server with the fewest active connections.
- IP Hashing: Keeps the same client mapped to the same server, useful for session persistence.
Load balancers are also essential for ensuring fault tolerance. If one node fails, the load balancer detects the health check failure and automatically reroutes traffic to healthy nodes.
While load balancers manage traffic, the system’s performance often hinges on how you store and retrieve data.
Database design and storage choices
Databases are the backbone of every system, but your choice depends on the workload. You must decide between structure and flexibility, and between strong consistency and high availability.
- Relational databases (SQL): SQL databases like MySQL or PostgreSQL are best for structured data and scenarios requiring ACID properties like Atomicity, Consistency, Isolation, and Durability. They are ideal for user profiles, billing, and inventory systems where data integrity is paramount.
- Non-relational databases (NoSQL): NoSQL databases like MongoDB or Cassandra are ideal for large-scale, unstructured data with high read and write demands. They often follow the BASE model, which stands for Basically Available, Soft state, and Eventual consistency. They prioritize availability and partition tolerance over immediate consistency.
- Sharding and partitioning: As data grows, a single server cannot hold it all. Sharding splits data across multiple servers based on a key, like UserID. This allows the database to scale horizontally but makes complex queries like joins more difficult.
- Replication: Replication involves maintaining multiple copies of data. Primary-replica replication allows writes to a single node and reads from multiple nodes, boosting read performance. Multi-master replication allows writes to any node, improving availability but complicating conflict resolution.
Even with scalable databases, disk I/O is slow. To achieve millisecond latency, you need caching.
Caching strategies
Caching is one of the most powerful System Design fundamentals for improving performance. It stores copies of data in high-speed memory, closer to the application.

Caches reduce the need to repeatedly query slow databases. By serving data from RAM, you can reduce latency from tens of milliseconds to single-digit milliseconds (or sub-millisecond for in-process caches) and significantly lower the load on your primary database. Here are some common types of cache:
- Application cache: Stored in memory within the service instance itself. Fast, but not shared between nodes.
- Distributed cache: Shared across nodes (e.g., Redis cluster). Slower than local cache but ensures consistency across the fleet.
- CDN cache: Delivers static assets (images, CSS, video) from geographically close servers to the user.
Caches must be updated when data changes to prevent users from seeing stale content. A common strategy is time-to-live (TTL), where data expires automatically. Another option is write-through caching, which writes to the cache first and synchronously persists to the database, reducing read misses at the cost of higher write latency.
Caching speeds up data retrieval, but finding the right data in a massive dataset requires efficient indexing.
Indexing for faster lookups
Indexing optimizes data retrieval, allowing systems to locate information quickly without scanning the entire database. It is the difference between reading every page of a book to find a word and looking it up in the index. Let’s look at some frequently used indexes:
- B-tree indexes: The standard for relational databases, excellent for range queries and equality checks.
- Inverted indexes: The backbone of search engines (like Elasticsearch), mapping words to the documents containing them.
- Trie structures: Specialized trees used in autocomplete System Design to quickly find strings with a common prefix.
Efficient indexing enables systems like Google Search and LinkedIn’s suggestions. However, indexes come with a cost. They slow down write operations because the index must be updated every time data changes.
Designing distributed systems involves navigating fundamental limitations, the most famous of which is the CAP theorem.
Consistency, availability, and partition tolerance
Distributed systems face unavoidable trade-offs, summarized by the CAP theorem. It states that a distributed data store can only provide two of the following three guarantees simultaneously.

- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped or delayed by the network.
In a distributed system, network partitions are inevitable. During a network partition, you must choose between consistency (CP) and availability (AP). Banking systems prioritize consistency (CP), while social feeds favor availability (AP). Understanding this trade-off is essential for interview success.
Beyond theoretical limits, you must also optimize for raw speed and volume.
Latency and throughput optimization
Two critical metrics define performance. Latency is the time it takes for the system to respond. Throughput is the number of requests it can handle per second.
To optimize these metrics, you must look at every layer of the stack. Use caching to reduce network round-trip times and precompute results for common queries. Optimize database indices to improve read performance. On the network layer, compress data and batch network calls to reduce overhead.
Modern systems also optimize communication protocols. While REST is standard, internal services might use gRPC with Protocol Buffers for smaller payloads and faster serialization. Others might use WebSockets for persistent, real-time connections.
Speed is important, but it means nothing if the system is down.
Reliability and fault tolerance
Failures are inevitable in distributed systems. Hard drives crash, networks lag, and code has bugs. A reliable system is designed to tolerate these failures without collapsing. We use the following strategies to achieve reliability and fault tolerance.
- Replication: Duplicate services or data so that if one node fails, another takes over.
- Retry and backoff: Automatically reattempt failed requests with exponential delays to avoid overwhelming a struggling service.
- Circuit breakers: Prevent cascading failures by temporarily blocking requests to a failing service, giving it time to recover.
- Rate limiting: Protects your services from being overwhelmed by too many requests from a single user or bot.
Reliable systems degrade gracefully. If the recommendation engine fails, the homepage should display a generic list of popular items instead of a 500 error page. To know when failures happen, you need visibility.
Observability and monitoring
Visibility into your system’s performance is vital. You cannot fix what you cannot measure. Observability goes beyond simple uptime checks. It involves understanding the system’s internal state from its external outputs.
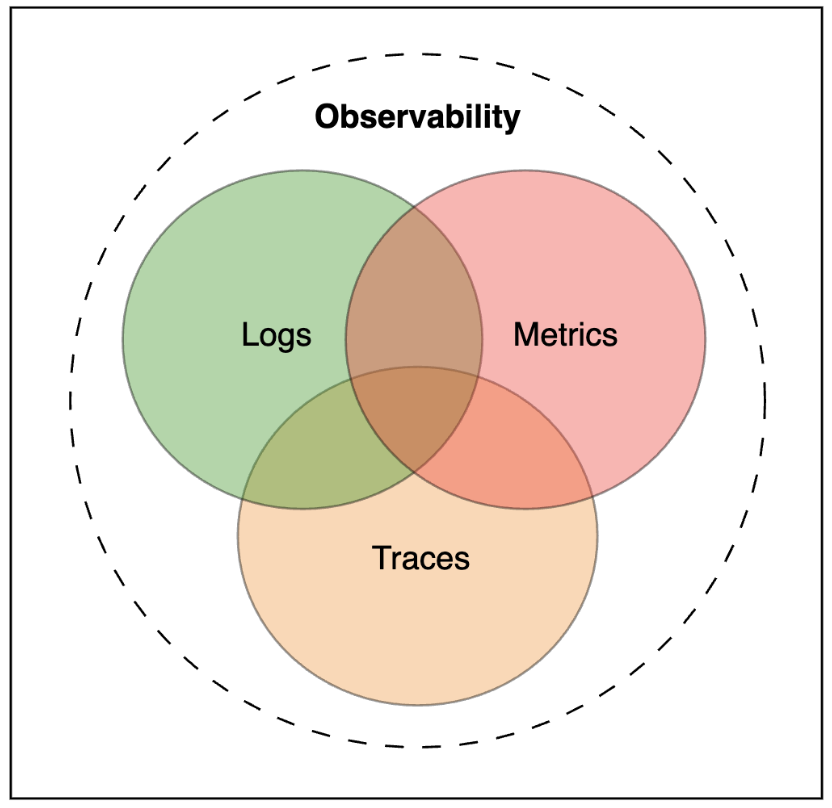
There are three main pillars of observability, as illustrated above.
- Metrics: Aggregated data over time (e.g., requests per second, CPU usage). Tools like Prometheus and Grafana are standard here.
- Logs: Discrete events that happened (e.g., “Database connection failed”).
- Tracing: Tracks a single request as it hops between microservices (distributed tracing), helping pinpoint exactly where latency or errors occur.
In production, observability is your safety net. It helps you detect performance degradation before users do.
Data pipelines and streaming
Modern systems process real-time data continuously. It is no longer enough to process data once a day. Users expect immediate feedback.
Batch processing aggregates data periodically using tools like Hadoop or Spark. It is efficient for high-volume, non-urgent data, like generating daily reports or training machine learning models.
On the other hand, stream processing processes events as they happen using tools like Kafka or Flink. It enables real-time features. For example, some System Designs use stream processing to update autocomplete suggestions dynamically or detect fraud the moment a transaction occurs.
Now, let’s see how all these components come together in a practical scenario.
Case study: A scalable search suggestion system
Let’s apply the fundamentals to a concrete case. Imagine designing a search suggestion feature for a large e-commerce site.
The system must generate contextually relevant search suggestions for each keystroke while maintaining sub-100 ms latency, even under millions of concurrent users and highly skewed traffic toward popular prefixes.
Here’s how the high-level architecture will look.
- Frontend: Captures user keystrokes and sends prefix queries to the backend using a persistent WebSocket or optimized HTTP requests.
- Backend: Routes requests to a dedicated suggestion service responsible for prefix matching and ranking.
- Cache: Uses Redis to store popular prefixes (for example,
iph → iphone, ipad) to serve frequent queries with minimal latency. - Storage: Maintains a trie or prefix-optimized inverted index to efficiently retrieve candidate suggestions for cache misses.
When a user types “lap,” the request is routed by a load balancer to the nearest application server, which first checks Redis for cached suggestions. On a cache hit, results are returned immediately. On a miss, the server queries the trie index, computes the top suggestions, updates the cache, and sends the response back to the user, all within strict latency constraints.
This example ties every fundamental concept, including caching, indexing, scalability, and fault tolerance, into a cohesive System Design.
Trade-offs in System Design
Every architecture involves compromises. There is no perfect system, only the one that best fits the specific constraints of the problem.
| Concern | Trade-off |
| Latency vs. freshness | Cached data is fast but may be outdated. |
| Consistency vs. availability | Strong consistency can increase latency and may reduce availability during partitions. |
| Cost vs. scalability | More replicas and servers increase infrastructure costs. |
| Complexity vs. maintainability | Highly optimized microservices are harder to debug than monoliths. |
| REST vs. gRPC | REST is readable and standard; gRPC is faster but requires schema management. |
During interviews, explicitly calling out these trade-offs demonstrates deep understanding. It shows you are not just memorizing patterns but evaluating them critically.
System Design fundamentals in interviews
When tackling interview questions, structure is your best friend. A chaotic answer suggests a chaotic thought process.
- Clarify requirements: Always confirm what the system should do and identify the constraints.
- Estimate scale: Approximate users, requests per second, and data size to decide if you need sharding or caching.
- Define APIs and data models: Show how components interact and what data is exchanged.
- Design high-level architecture: Use diagrams to explain the flow of data.
- Discuss bottlenecks: Identify single points of failure and propose mitigations like replication.
- Consider trade-offs: Explain why you chose a NoSQL database over SQL, or why you used eventual consistency.
Interviewers value reasoning more than perfect solutions. Demonstrating how you apply System Design fundamentals is what gets you hired.
Key takeaways and resources
Strong System Design starts with mastering fundamentals, because they underpin every scalable and resilient architecture you will encounter. Effective designs always balance the core triad of scalability, availability, and performance, leveraging tools such as caching, indexing, and partitioning to achieve efficiency at scale.
Just as important is the ability to recognize and articulate trade-offs clearly, since no real-world system can optimize every dimension simultaneously. Mastering these fundamentals equips you to approach any System Design interview with confidence, as you will understand the recurring patterns behind large-scale systems.
To apply these ideas to real-world systems such as caching layers, search, or notification pipelines, practice with well-known design problems. Resources like the Grokking the System Design Interview course walk through dozens of interview-ready scenarios and help you practice both designing systems and communicating your reasoning clearly. You can also choose study material that best fits your experience level from the resources below.
