When you begin learning System Design, you quickly realize that scalability is not just about adding more servers. It is about understanding how a single machine behaves under pressure before you ever distribute the load. The C10K problem forces you to confront this reality head-on by asking a deceptively simple question: how can one server handle ten thousand concurrent client connections efficiently?
The C10K problem is not merely a historical curiosity from the early days of the internet. It represents a turning point in how engineers think about concurrency, operating systems, and network programming. Even though modern systems now aim for C100K or even C1M, the foundational ideas you learn from C10K are exactly what interviewers expect you to understand when discussing high-scale architectures.
If you are preparing for System Design interviews, mastering the C10K problem gives you a strong mental model for reasoning about bottlenecks, resource constraints, and architectural tradeoffs. You are not just memorizing patterns; you are understanding why certain patterns exist in the first place. That depth of understanding is what separates a surface-level candidate from a strong systems thinker.
What Is The C10K Problem?

The C10K problem refers to the challenge of designing a system capable of handling ten thousand concurrent client connections on a single server. At first glance, this might not seem extraordinary, especially in today’s cloud-native world. However, when this problem was first articulated, most servers could barely handle a fraction of that load without collapsing under thread overhead and context switching.
To understand why C10K matters, you need to focus on the word concurrent. These are not ten thousand total requests over time, but ten thousand active connections at once. Each connection consumes memory, file descriptors, and CPU cycles, which quickly expose the limitations of naive multi-threaded architectures.
Why It Is Still Relevant In Modern Systems
Even though hardware has improved dramatically, the underlying constraints have not disappeared. CPU cores are finite, memory is limited, and operating systems still impose file descriptor caps and scheduling overhead. The same fundamental bottlenecks that defined C10K continue to influence how you design APIs, gateways, proxies, and backend services today.
When you design a chat server, a real-time analytics platform, or an API gateway, you are effectively solving a modern version of the C10K problem. Interviewers may not explicitly say “C10K,” but when they ask how your system handles 100,000 simultaneous users, they are testing whether you understand these concurrency principles. If you grasp C10K deeply, you can scale your reasoning confidently to C100K and beyond.
Origins And History: From C10K To Today
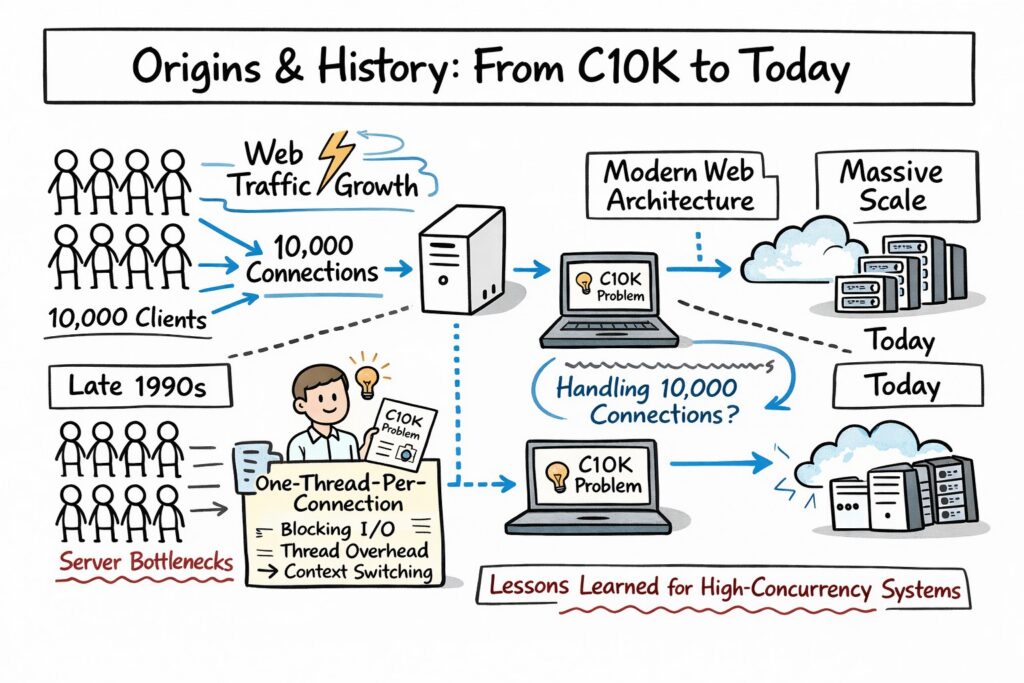
To truly appreciate the C10K problem, you need to understand the environment in which it emerged. In the late 1990s, web traffic was growing rapidly, but server architectures were still heavily reliant on blocking I/O and one-thread-per-connection models. These models worked well at a small scale but became catastrophic as connection counts increased.
The term “C10K problem” was popularized by Dan Kegel in 1999, when he published an article discussing techniques for handling ten thousand concurrent connections. His work highlighted how traditional approaches using threads and blocking sockets were inefficient for high-concurrency workloads. That article became a reference point for performance-focused engineers worldwide.
The Early Internet Bottleneck
In the early days of web servers like Apache, the dominant model was process-per-connection or thread-per-connection. Every new client connection resulted in the creation of a new thread or process. While conceptually simple, this approach introduced significant overhead in memory allocation and context switching.
As traffic scaled, systems began to thrash under the weight of thousands of threads. Each thread consumed stack memory, and the operating system scheduler struggled to efficiently manage context switches. Instead of improving throughput, adding more connections often degraded performance dramatically.
The table below illustrates why thread-per-connection architectures struggled at scale:
| Resource Factor | Impact At Low Concurrency | Impact At High Concurrency |
|---|---|---|
| Thread Memory Usage | Minimal | Significant Memory Pressure |
| Context Switching Overhead | Negligible | CPU Saturation |
| Scheduler Complexity | Manageable | Scheduling Bottlenecks |
| File Descriptor Usage | Stable | Risk Of Exhaustion |
When you look at this comparison, you begin to see why C10K was a serious challenge rather than a marketing term. The limitations were structural, not accidental.
Evolution To C100K And Beyond
As operating systems introduced more efficient I/O mechanisms such as epoll on Linux and kqueue on BSD systems, the landscape changed dramatically. Event-driven models replaced naive threading approaches, allowing a single thread to manage thousands of connections using non-blocking I/O. This innovation marked a shift from hardware scaling to architectural optimization.
Modern frameworks like Node.js, Nginx, and high-performance Go servers are direct descendants of this evolution. They rely heavily on event loops and asynchronous execution to manage concurrency efficiently. Although the numbers have grown from ten thousand to millions of connections in some cases, the intellectual foundation remains rooted in the C10K problem.
When you discuss scalability in interviews today, you are standing on the shoulders of this historical shift. Understanding how and why this transition happened gives your answers depth and credibility.
The Core Challenge: What Makes Handling 10,000 Connections Hard
If you want to master the C10K problem, you must internalize why handling ten thousand connections is fundamentally difficult. The difficulty does not come from network bandwidth alone. It arises from how operating systems allocate resources and schedule work across limited hardware.
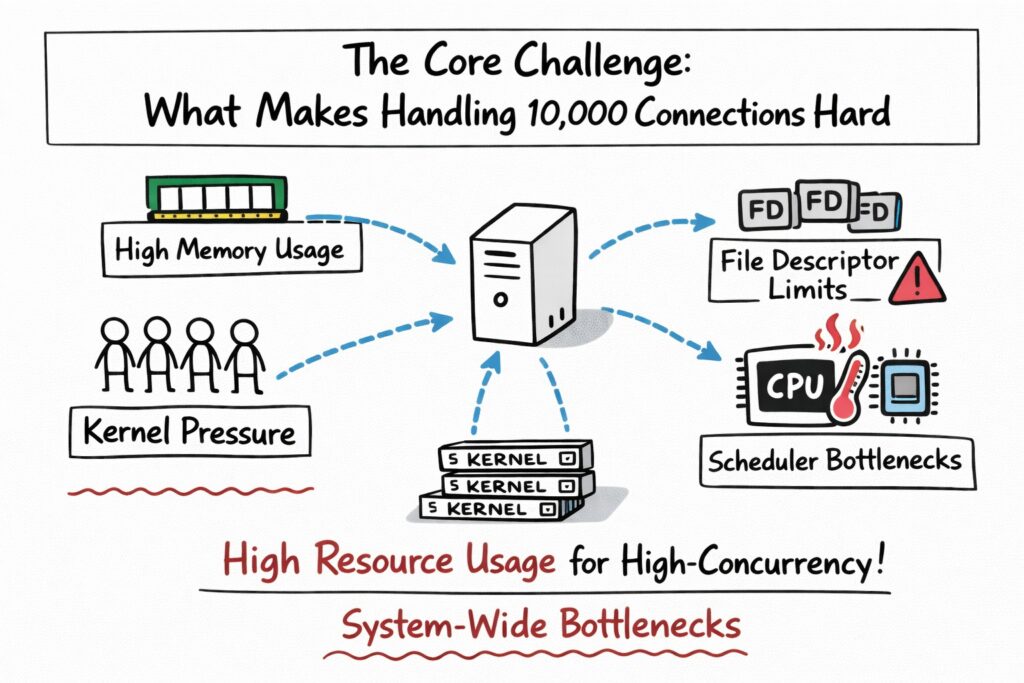
At its core, the challenge is about resource management under concurrency pressure. Each open connection requires memory buffers, kernel bookkeeping, and file descriptors. When multiplied by thousands, even small inefficiencies become system-wide bottlenecks.
CPU And Context Switching Costs
One of the most underestimated costs in naive concurrency models is context switching. When you spawn thousands of threads, the operating system must frequently pause one thread and resume another. This process consumes CPU cycles that could otherwise be used for actual request processing.
As concurrency increases, the scheduler overhead grows non-linearly. Instead of scaling gracefully, performance can plateau or even degrade. You may think you are increasing capacity, but you are actually increasing administrative overhead.
Memory Consumption And File Descriptors
Every connection consumes memory for buffers and metadata. In thread-per-connection models, each thread also requires its own stack space, which can easily be several megabytes per thread depending on configuration. Multiply that by ten thousand, and you are suddenly dealing with gigabytes of memory usage.
File descriptors also become a limiting factor. Operating systems impose limits on how many open file descriptors a process can maintain. If you fail to configure these limits properly, your server may begin rejecting connections long before the CPU becomes the bottleneck.
The following table summarizes key resource constraints:
| Resource Type | Why It Matters | Failure Mode At Scale |
|---|---|---|
| CPU | Handles request processing | Scheduler Saturation |
| Memory | Buffers And Thread Stacks | Out-Of-Memory Errors |
| File Descriptors | Tracks Open Connections | Connection Refusal |
| Network Buffers | Stores Inbound And Outbound Data | Packet Drops Or Latency Spikes |
Understanding these constraints allows you to reason clearly about system behavior during interviews.
Blocking Versus Non-Blocking I/O
Blocking I/O means that when a thread waits for data from a socket, it cannot do anything else. This model is simple but inefficient at scale because many connections are idle most of the time. You end up dedicating expensive resources to connections that are not actively transmitting data.
Non-blocking I/O changes the game by allowing a single thread to monitor multiple sockets simultaneously. Instead of waiting, the thread checks which connections are ready for reading or writing and processes them accordingly. This shift dramatically reduces idle resource consumption and forms the backbone of modern high-concurrency servers.
Key Concepts In High-Concurrency Network Design
Before you can confidently design scalable systems, you need a solid grasp of the conceptual building blocks behind C10K solutions. These concepts appear repeatedly in System Design interviews, especially when discussing APIs, gateways, and real-time services.
If you internalize these ideas, you will find yourself reasoning more clearly about bottlenecks and scaling strategies. Instead of memorizing patterns, you will understand why they work.
Concurrency Versus Parallelism
Concurrency refers to managing multiple tasks that make progress over time, even if they are not executing simultaneously. Parallelism, on the other hand, involves executing multiple tasks at the same time using multiple CPU cores. In the context of C10K, you are often more concerned with concurrency than pure parallel execution.
When you design for ten thousand connections, most of those connections are idle at any given moment. Your goal is to manage them efficiently rather than execute all of them simultaneously. Recognizing this distinction helps you avoid over-engineering with unnecessary threads or processes.
The following comparison clarifies the distinction:
| Concept | Focus | Typical Use In C10K Context |
|---|---|---|
| Concurrency | Managing Many Tasks Efficiently | Event Loops, Async I/O |
| Parallelism | Executing Tasks Simultaneously | Multi-Core Computation |
When interviewers ask how you would scale a server, demonstrating that you understand this difference shows maturity in your thinking.
Event Loops And Reactor Patterns
An event loop continuously checks for events such as incoming network data or completed I/O operations. When an event occurs, it dispatches the corresponding handler function. This model allows a single thread to manage thousands of connections without blocking.
The Reactor pattern builds on this idea by demultiplexing events and dispatching them to handlers. Operating system primitives such as epoll and kqueue enable efficient monitoring of large numbers of file descriptors. Instead of polling each socket individually, the kernel notifies your application when a socket is ready.
This architectural shift is the heart of modern scalable servers. When you explain this clearly in an interview, you demonstrate that you understand not just distributed systems but also low-level performance engineering.
OS-Level Primitives: Epoll, Kqueue, And IOCP
High-concurrency servers rely on operating system mechanisms that efficiently monitor multiple file descriptors. On Linux, epoll provides scalable event notification. On BSD systems and macOS, kqueue serves a similar purpose. On Windows, IOCP enables asynchronous I/O with completion ports.
These primitives eliminate the inefficiencies of older models like select and poll, which did not scale well to thousands of descriptors. When you mention these mechanisms in interviews, you signal that your understanding goes beyond surface-level architecture diagrams.
By mastering these foundational concepts, you equip yourself with the intellectual tools necessary to design systems that scale far beyond C10K. More importantly, you develop the confidence to reason through high-concurrency challenges methodically rather than guessing at solutions.
Architectures That Scale Past C10K
Once you understand why traditional thread-per-connection models fail, you are ready to explore architectures that scale far beyond the original C10K threshold. This is where System Design becomes deeply practical, because the patterns you learn here are directly applicable to API gateways, chat systems, streaming services, and real-time collaboration platforms. When interviewers ask how you would design a system for 100,000 concurrent users, they expect you to lean on these architectural principles.
Scaling past C10K is not about brute force hardware upgrades. It is about structuring your application so that it uses operating system primitives efficiently, minimizes idle resource consumption, and distributes work intelligently across threads and processes.
Event-Driven Architectures
Event-driven architecture is one of the most important breakthroughs in solving high-concurrency challenges. Instead of dedicating one thread per connection, you use a small number of threads that react to events such as incoming data, completed writes, or timeout triggers. This approach allows a single thread to manage thousands of connections without blocking.
When you adopt an event-driven model, your application logic becomes structured around callbacks or handlers. Each time a socket becomes readable or writable, the event loop dispatches control to the appropriate handler. This keeps the CPU focused on active work rather than waiting on idle connections.
The impact of this shift is significant because you dramatically reduce context switching and memory overhead. Your system becomes more predictable under load, and you avoid the explosive growth in thread stacks that plagued earlier models.
Reactor Versus Proactor Patterns
As you go deeper into scalable network design, you encounter two core architectural patterns: Reactor and Proactor. Both aim to manage high concurrency efficiently, but they differ in how they handle I/O events and execution flow.
In the Reactor pattern, the system waits for I/O readiness events and then performs the actual read or write operation. In contrast, the Proactor pattern initiates asynchronous operations and gets notified when they complete. Understanding this distinction helps you explain design decisions clearly in interviews.
The table below clarifies the difference between the two:
| Pattern | How It Works | Typical Usage Scenario |
|---|---|---|
| Reactor | Waits For I/O Readiness, Then Performs Operation | Common In Linux With Epoll |
| Proactor | Initiates Async Operation, Notified On Completion | Often Used In Windows IOCP |
When you discuss these patterns during an interview, you demonstrate that you are thinking at the operating system integration level rather than just at the framework level. That depth of reasoning immediately strengthens your System Design credibility.
Thread Pools And Hybrid Models
Pure event-driven models are powerful, but they are not always sufficient on their own. When your system must perform CPU-intensive tasks such as encryption, JSON parsing, or image processing, you cannot rely entirely on a single event loop thread. In such cases, hybrid architectures that combine event loops with thread pools become essential.
You use the event loop to manage connections and delegate CPU-bound work to worker threads. This ensures that heavy computation does not block the main loop, preserving responsiveness. The separation between I/O handling and computation is a key architectural principle in scalable systems.
This hybrid model appears frequently in production-grade servers. When you explain this tradeoff in an interview, you show that you understand both theoretical concurrency and practical performance engineering.
The Role Of Reverse Proxies And Load Balancers
Scaling past C10K also involves external architectural components. Reverse proxies such as Nginx or Envoy sit in front of application servers and handle connection termination, SSL processing, and request routing. This allows backend services to focus purely on business logic.
By offloading connection management and TLS negotiation to optimized proxies, you significantly reduce the resource burden on application nodes. This layered architecture improves fault isolation and makes horizontal scaling more manageable.
When you design systems in interviews, incorporating a reverse proxy or load balancer into your architecture demonstrates maturity. It signals that you understand how real-world production systems distribute responsibility across layers.
Case Studies: Systems That Handle Massive Connections
Theory becomes powerful when you see it in action. Modern high-scale systems are living proof that the C10K problem was not just solved, but surpassed many times over. By studying real systems, you sharpen your intuition for scalable design decisions.
When you reference real-world examples in interviews, you anchor your answers in practical engineering rather than abstract theory. This makes your reasoning more persuasive and grounded.
Nginx And High-Performance Web Servers
Nginx is one of the most cited examples of an event-driven server designed to handle massive concurrency. Unlike early Apache versions that relied on process-per-request models, Nginx uses a small number of worker processes with event loops. Each worker can manage thousands of connections efficiently using non-blocking I/O.
This design drastically reduces memory consumption and context switching overhead. Because of its efficient architecture, Nginx became the backbone of high-traffic websites and reverse proxy deployments worldwide.
When you analyze Nginx, you see a direct implementation of C10K principles. The server does not attempt to parallelize everything; it focuses on managing concurrency intelligently.
Kafka And Messaging Systems
Apache Kafka demonstrates how high-concurrency design extends beyond web servers. Kafka brokers handle thousands of client connections for producers and consumers while maintaining high throughput and durability guarantees. It achieves this through efficient network I/O and careful batching strategies.
Kafka relies heavily on sequential disk writes and efficient socket management. By optimizing for throughput and minimizing random disk access, it balances concurrency with performance constraints.
This example teaches you that solving C10K is not just about sockets but also about end-to-end System Design. You must consider storage, replication, and coordination when scaling communication-heavy systems.
Real-Time Systems And WebSocket Services
Real-time systems such as chat applications or multiplayer game servers often maintain persistent connections with clients. These systems can easily exceed tens of thousands of simultaneous WebSocket connections. Managing these connections requires careful event loop management and efficient memory usage.
Unlike short-lived HTTP requests, persistent connections amplify resource pressure. Each idle WebSocket still consumes memory and file descriptors. Designing for this environment forces you to apply C10K principles rigorously.
When discussing such systems in interviews, you can explain how persistent connections influence scaling strategy. That insight demonstrates that you understand how workload characteristics shape architecture.
Performance Tradeoffs And Design Decisions
High-concurrency systems are defined by tradeoffs. You rarely optimize for everything simultaneously. Instead, you make deliberate decisions about what matters most in your context.
When you prepare for System Design interviews, learning to articulate tradeoffs is more important than memorizing solutions. Interviewers want to see whether you understand why certain decisions are made, not just what those decisions are.
Latency Versus Throughput
Latency measures how long a single request takes, while throughput measures how many requests you can handle per unit of time. Optimizing for one can negatively impact the other. For example, batching requests can improve throughput but increase latency.
In high-concurrency systems, you often prioritize throughput while maintaining acceptable latency. Understanding where to draw that line depends on the application’s requirements.
The table below highlights this tradeoff:
| Metric | Focus | Typical Optimization Strategy |
|---|---|---|
| Latency | Speed Of Individual Request | Reduce Blocking And Queuing |
| Throughput | Requests Per Second | Batch Processing And Async I/O |
When you clearly explain this tradeoff during interviews, you show that you think beyond simplistic performance metrics.
Memory Usage And Buffer Management
Buffers are necessary for storing inbound and outbound data. However, allocating large buffers for every connection can quickly exhaust memory at scale. Efficient buffer reuse and pooling strategies are critical in high-concurrency servers.
You must balance memory efficiency with safety and performance. Aggressive reuse can introduce complexity, while naive allocation wastes resources. This tension is central to designing systems that scale gracefully.
When you explain buffer management decisions in interviews, you demonstrate attention to low-level resource economics.
Backpressure And Flow Control
As concurrency increases, downstream systems may struggle to keep up. Backpressure mechanisms allow a system to signal upstream components to slow down. Without backpressure, queues grow unbounded, and latency spirals out of control.
Flow control mechanisms help stabilize high-load systems. They ensure that producers do not overwhelm consumers and that resources remain within safe limits.
Understanding backpressure is particularly impressive in interviews because it shows you think about failure modes. Scalable systems are not just about peak performance but about maintaining stability under stress.
Monitoring, Metrics, And Bottleneck Identification
Designing a scalable system is only half the challenge. You must also measure its behavior under load and detect bottlenecks before they cause outages. Monitoring transforms theoretical scalability into operational reliability.
When you discuss monitoring in interviews, you demonstrate production awareness. You show that you think about systems not just as diagrams but as living, evolving entities.
Key Metrics To Track
High-concurrency systems require visibility into connection counts, CPU utilization, memory usage, and latency percentiles. Tracking averages alone is insufficient because tail latency often reveals hidden bottlenecks.
Connection counts tell you how close you are to file descriptor limits. CPU usage reveals whether you are compute-bound or I/O-bound. Memory consumption indicates whether buffer management is sustainable.
The table below summarizes essential metrics:
| Metric | Why It Matters |
|---|---|
| Active Connections | Indicates Concurrency Pressure |
| CPU Utilization | Reveals Compute Bottlenecks |
| Memory Usage | Highlights Resource Saturation |
| P95/P99 Latency | Exposes Tail Performance Issues |
When you articulate these metrics clearly, you show that you understand how to validate system scalability in real environments.
Detecting Saturation Early
Systems rarely fail without warning. Rising latency, increasing queue lengths, and steady growth in memory usage are early indicators of stress. Proactively detecting these signals allows you to scale or optimize before outages occur.
Load testing is another essential practice. By simulating high concurrency scenarios, you can observe how your system behaves under controlled stress conditions. This practice reinforces your understanding of the C10K problem beyond theory.
Scaling Triggers And Operational Decisions
Scaling decisions should be based on measurable thresholds rather than guesswork. You might scale horizontally when CPU utilization exceeds a sustained threshold or when connection counts approach configured limits.
Defining clear scaling triggers improves reliability and cost efficiency. It ensures that your system responds predictably to growth rather than reacting chaotically during traffic spikes.
When you discuss monitoring and scaling triggers in interviews, you demonstrate operational maturity. You show that you understand not just how to design scalable systems, but how to keep them healthy in production.
Practical Code And System Patterns
At some point, theory must translate into implementation. If you truly understand the C10K problem, you should be able to explain how it shapes real code decisions and service architecture. Interviewers often probe here because they want to see whether you can connect high-level System Design to practical engineering tradeoffs.
When you move from whiteboard diagrams to actual code, you quickly realize that concurrency models are not abstract ideas. They directly influence how you structure your server loop, manage memory, and handle client lifecycle events.
Designing A Scalable TCP Server
If you were to implement a scalable TCP server today, you would likely rely on non-blocking sockets and an event loop. Instead of spawning a thread for each connection, you would register sockets with an event multiplexer such as epoll and react only when the kernel signals readiness.
This design keeps your application responsive even when thousands of connections are idle. The event loop processes only active sockets, ensuring that CPU cycles are not wasted waiting for network data.
The architectural comparison below illustrates why this shift matters:
| Model | Thread Usage | Scalability Characteristics |
|---|---|---|
| Thread-Per-Connection | One Thread Per Client | High Memory And CPU Overhead |
| Event-Driven Architecture | Few Threads With Event Loop | Efficient At High Concurrency |
When you explain this difference clearly in an interview, you demonstrate that you understand how system-level decisions affect performance at scale.
Async Frameworks And Modern Languages
Modern runtimes such as Node.js, Go, and Rust embed C10K lessons directly into their design. Node.js relies on a single-threaded event loop with asynchronous I/O, making it naturally suited for I/O-bound workloads. Go uses lightweight goroutines with an efficient scheduler, allowing massive concurrency with lower overhead than traditional threads.
Rust, with async runtimes like Tokio, provides fine-grained control over memory and execution while leveraging non-blocking I/O. Each of these ecosystems reflects a different approach to the same fundamental challenge of handling many concurrent connections efficiently.
When discussing these tools in interviews, you should avoid simply naming them. Instead, explain why their concurrency models align well with high-connection workloads. That reasoning reveals depth rather than surface familiarity.
Common Anti-Patterns To Avoid
Many scalability failures stem from avoidable mistakes. Blocking database calls inside an event loop, allocating unbounded buffers, or ignoring file descriptor limits can quickly collapse an otherwise sound architecture.
Understanding anti-patterns strengthens your credibility in interviews because it shows that you think about failure modes. You are not just designing for success but also guarding against predictable bottlenecks.
If you can explain how a blocking call inside an event loop stalls all connections, you show that you truly understand concurrency dynamics. That clarity often distinguishes strong candidates from average ones.
Scaling Horizontally: Beyond One Machine
Solving the C10K problem on a single machine is an important milestone, but modern systems rarely stop there. Once traffic grows beyond what one node can handle, you must scale horizontally. This introduces new dimensions of complexity, including coordination, state management, and distributed consistency.
When interviewers shift from single-node performance to distributed scaling, they are testing whether you can extend C10K reasoning into multi-node systems. The same resource-awareness mindset still applies, but the surface area expands.
Stateless Services And Session Handling
Stateless services simplify horizontal scaling because any node can handle any request. If your application server does not store session data locally, you can distribute traffic evenly across instances using a load balancer.
For stateful workloads such as WebSocket connections, you must carefully consider session affinity or shared state stores. This often involves externalizing session data to systems like Redis so that connections can be managed independently of individual application nodes.
The following table clarifies the difference:
| Architecture Type | Scaling Complexity | Operational Flexibility |
|---|---|---|
| Stateful Service | Higher | Limited By Local State |
| Stateless Service | Lower | Easily Load Balanced |
Understanding this distinction allows you to articulate horizontal scaling strategies confidently in interviews.
Sharding And Partitioning
When traffic exceeds the capacity of a single database or service instance, partitioning becomes necessary. Sharding distributes data across multiple nodes based on a key such as user ID or geographic region.
This approach reduces per-node load and improves concurrency capacity. However, it introduces new challenges such as cross-shard queries and rebalancing.
In interviews, explaining sharding in the context of connection-heavy systems demonstrates holistic thinking. You show that you understand how backend storage and front-end concurrency interact.
Global Load Balancing And Edge Distribution
At a very large scale, traffic often originates from multiple geographic regions. Global load balancing and CDN-based edge termination reduce latency and distribute connection pressure closer to users.
This layered approach improves both performance and resilience. If one region experiences failure, traffic can be rerouted to healthy zones.
When you describe this architecture clearly, you signal that your thinking extends beyond single data centers. That broader systems perspective is highly valued in senior-level interviews.
Interview Strategy: How To Talk About C10K
Understanding the C10K problem is valuable, but being able to communicate that understanding clearly is equally important. In interviews, your explanation must be structured, logical, and persuasive.
When faced with a high-concurrency design question, you should begin by clarifying expected traffic patterns. Ask how many concurrent users, what type of workload, and whether connections are short-lived or persistent. This immediately shows structured thinking.
Framing Your Answer
Start with constraints before jumping into solutions. Mention CPU, memory, file descriptors, and I/O limitations to demonstrate awareness of system boundaries. Then explain how event-driven models reduce overhead compared to naive thread-based approaches.
By explicitly naming tradeoffs, you elevate your answer from descriptive to analytical. Interviewers are not looking for memorized architectures but for structured reasoning.
Common Candidate Mistakes
Many candidates focus immediately on adding more servers without addressing single-node efficiency. Others ignore blocking operations or fail to mention backpressure and monitoring considerations.
When you avoid these pitfalls and discuss both architecture and operational safeguards, your answer becomes comprehensive. You show that you think like a production engineer rather than just a theoretical designer.
Whiteboard-Style Explanation Flow
A strong explanation often follows a natural progression from single-node optimization to distributed scaling. You describe event loops and non-blocking I/O first, then introduce load balancers and stateless services, and finally discuss sharding or caching if needed.
This layered explanation mirrors real-world scaling journeys. It also makes your interview answer feel cohesive and intentional rather than scattered.
Summary, Further Reading, And Next Steps
By now, you should see that the C10K problem is more than a historical footnote. It represents a foundational shift in how engineers design scalable network systems. Even though modern workloads easily exceed ten thousand connections, the principles that emerged from C10K remain central to System Design thinking.
If you are preparing for interviews, revisiting these fundamentals gives you a powerful advantage. Instead of memorizing distributed patterns blindly, you build from first principles rooted in resource constraints and concurrency models.
Key Takeaways From The C10K Journey
You learned that thread-per-connection models struggle due to context switching and memory overhead. You explored how event-driven architectures, non-blocking I/O, and OS primitives such as epoll enable efficient concurrency. You also examined how horizontal scaling extends these principles into distributed systems.
More importantly, you developed a structured way to reason about performance tradeoffs. This reasoning skill is exactly what System Design interviews aim to assess.
Where To Go From Here
If you want to deepen your mastery, explore topics such as C10M scalability, distributed tracing, and advanced load testing methodologies. You can also study production-grade open-source systems to see how concurrency is handled in real codebases.
Using structured prep resources effectively
Use Grokking the System Design Interview on Educative to learn curated patterns and practice full System Design problems step by step. It’s one of the most effective resources for building repeatable System Design intuition.
You can also choose the best System Design study material based on your experience:
Final Thoughts
The C10K problem teaches you humility in System Design. It reminds you that scalability begins with understanding constraints rather than assuming infinite resources. Every large-scale architecture, from global streaming platforms to real-time messaging systems, inherits lessons from this foundational challenge.
When you approach interviews with this mindset, you move beyond buzzwords and architectural diagrams. You demonstrate an ability to reason from the kernel level up to distributed systems. That layered understanding is what ultimately defines a strong System Design engineer.
If you internalize the principles behind the C10K problem, you will not just answer interview questions more effectively. You will design systems with clarity, efficiency, and confidence, grounded in the realities that shaped modern high-concurrency computing.
