When an interviewer asks you to design a pub sub system, they are not asking you to recreate Kafka, RabbitMQ, or Google Pub/Sub feature by feature. They are testing whether you understand event-driven architectures and distributed messaging fundamentals. This includes how to decouple producers from consumers, how to scale fan-out safely, and how to reason about correctness when systems fail.
Pub-sub systems sit at the heart of modern distributed platforms. They enable microservices communication, data pipelines, event sourcing, and real-time processing. Because so many systems depend on them, mistakes in a pub-sub design can cascade widely. Interviewers, therefore, look closely at how you reason about durability, ordering, delivery semantics, and backpressure.
Pub sub as infrastructure, not application logic
A strong answer frames pub sub as infrastructure, not business logic. Producers publish events without knowing who consumes them. Consumers process events without knowing who produced them. This loose coupling improves scalability and developer velocity, but it shifts complexity into the messaging system.
In interviews, it is important to explicitly state that the pub-sub system must remain reliable under partial failures, slow consumers, and uneven traffic patterns. The goal is not just to move messages quickly, but to do so predictably and safely.
Event streams versus point-to-point messaging
Interviewers often expect candidates to clarify whether they are designing a stream-based pub-sub system or a traditional queue. A pub-sub system typically supports fan-out, where multiple consumers receive the same message independently. This contrasts with work queues, where messages are consumed once.
Calling out this distinction early helps frame later decisions around storage, offsets, replay, and consumer groups.
Clarifying requirements and assumptions upfront
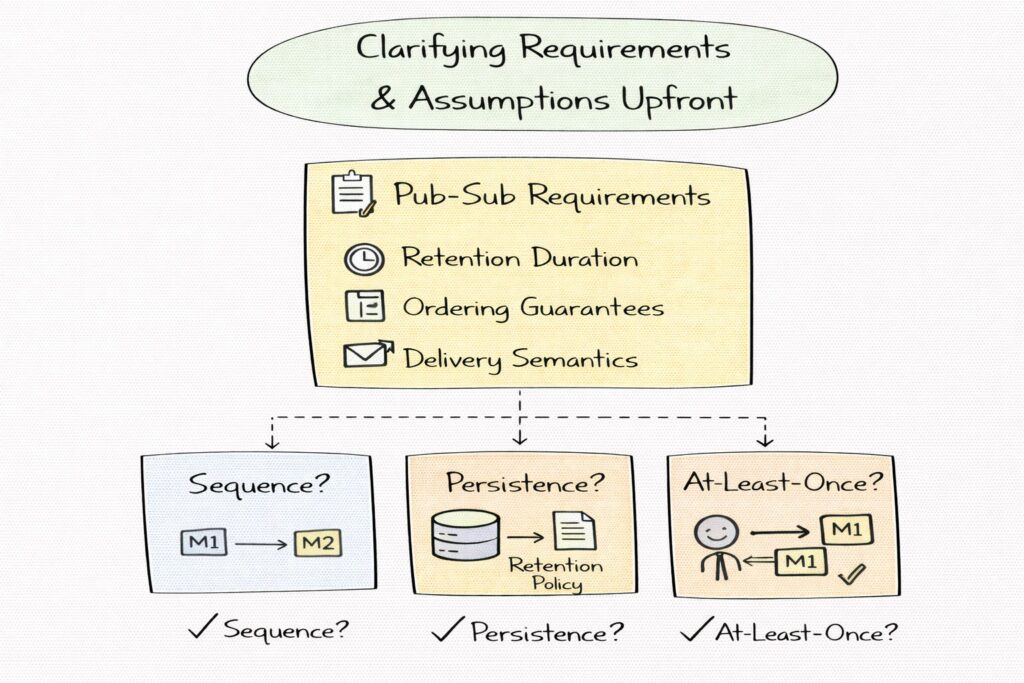
Pub-sub systems are highly configurable, and design choices depend heavily on requirements. Ordering guarantees, retention duration, and delivery semantics fundamentally change the architecture. Without clarifying these upfront, it is easy to design a system that is either overly complex or insufficiently robust.
In System Design interviews, this step demonstrates that you understand there is no one-size-fits-all pub-sub system.
Functional requirements to establish early
You should clarify whether the system supports topics, subscriptions, and consumer groups. Topics define logical streams of messages, while consumer groups enable load sharing among consumers. You should also establish whether consumers can replay messages from history or only receive new messages.
Filtering requirements matter as well. Some systems allow server-side filtering by attributes, while others push filtering logic to consumers. This affects broker complexity and performance.
Delivery semantics and ordering expectations
One of the most important clarifications is delivery semantics. At-most-once delivery sacrifices reliability for speed. At-least-once delivery guarantees delivery but allows duplicates. Exactly-once delivery is extremely complex and often only achievable within limited scopes.
Ordering expectations must also be clarified. Global ordering across all messages is expensive and limits scalability. Most real systems guarantee ordering only within a partition or key.
Interviewers pay close attention to how you articulate these trade-offs.
Non-functional requirements that drive design
Throughput and latency targets influence storage and replication strategies. Durability requirements determine whether messages must be persisted before acknowledgment. Multi-region support introduces replication and consistency challenges.
It is also important to clarify expected message sizes and retention duration. Large messages or long retention periods significantly impact storage and I/O design.
Reasonable assumptions when details are missing
If the interviewer leaves scope open, it is reasonable to assume a high-throughput, durable pub-sub system used for event-driven microservices. You can assume at-least-once delivery, per-partition ordering, replay support, and retention measured in days.
Stating assumptions clearly allows you to proceed confidently and gives the interviewer an opportunity to refine the scope.
High-level architecture overview
At a high level, a pub-sub system consists of producers that publish messages, brokers that receive and store messages, and consumers that subscribe to topics and process messages. Topics are divided into partitions to allow parallelism and scale.
In interviews, it helps to emphasize that brokers are stateful components. They manage storage, offsets, replication, and delivery coordination. This distinguishes pub-sub systems from stateless request-response architectures.
Data plane versus control plane separation
A mature pub sub design separates the data plane from the control plane. The data plane handles high-volume message ingestion and delivery. It must be fast, efficient, and resilient. The control plane manages metadata such as topic definitions, partition assignments, consumer group membership, and rebalancing.
Interviewers often look for this separation because it reflects real-world operational needs. Control plane failures should not immediately stop message flow.
End-to-end message flow
A typical flow begins when a producer publishes a message to a topic. The system routes the message to a specific partition, persists it, and acknowledges the producer based on durability guarantees. Consumers then read messages from partitions at their own pace, tracking progress via offsets.
Explaining this flow clearly helps anchor later discussions about ordering, replication, and backpressure.
Stateless producers and stateful brokers
Producers are typically stateless and simple. They batch messages, handle retries, and rely on brokers for durability. Brokers, on the other hand, maintain persistent logs and coordinate replication.
In interviews, calling out that complexity lives primarily in brokers shows that you understand where scaling and failure challenges arise.
Topic model, partitions, and message routing
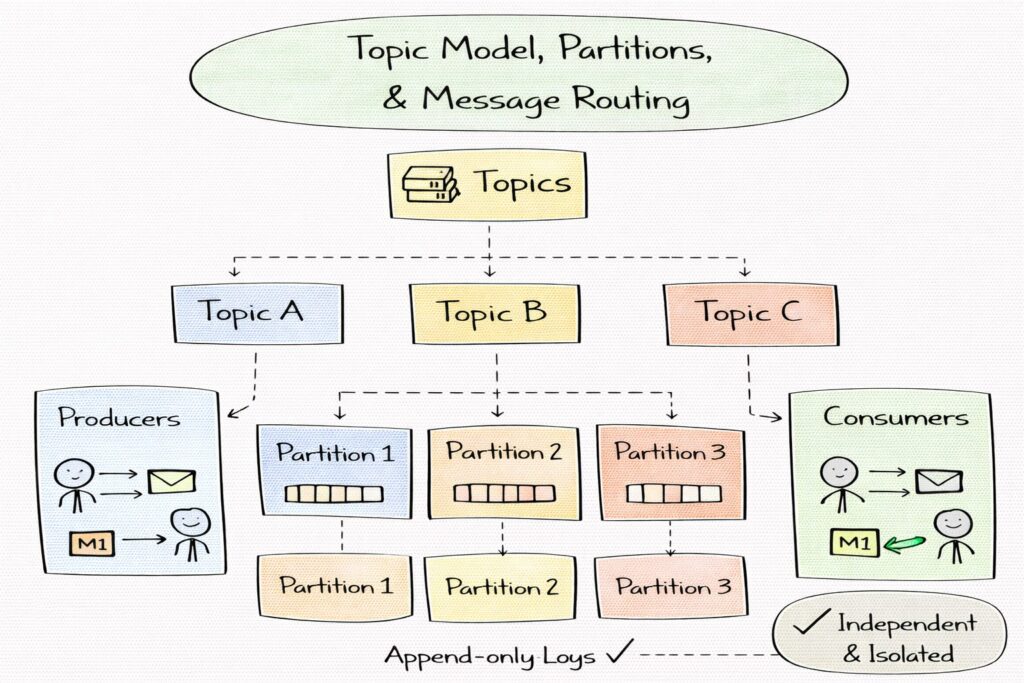
Topics represent logical streams of messages. They allow producers and consumers to agree on the semantic meaning of events without tight coupling. In interviews, it is important to explain that topics are not queues but append-only logs that multiple consumers can read independently.
Topics provide isolation. Problems in one topic should not affect others, which is critical for multi-tenant systems.
Partitioning for scalability and parallelism
Partitions are the primary mechanism for scaling a pub-sub system. Each partition is an ordered log, and partitions can be distributed across brokers. This allows producers to write and consumers to read in parallel.
A strong answer explains that partition count directly impacts throughput and consumer parallelism, but also increases metadata and operational complexity.
Partitioning strategies and routing decisions
When a producer publishes a message, the system must decide which partition it goes to. Round-robin routing balances load but provides no ordering guarantees across related messages. Key-based hashing routes messages with the same key to the same partition, preserving ordering for that key.
In interviews, explaining why key-based partitioning is common for event streams shows practical understanding.
Ordering guarantees and their scope
Ordering is guaranteed only within a single partition. There is no global ordering across partitions. This trade-off enables horizontal scaling while still providing useful guarantees for many use cases.
Interviewers often test whether candidates mistakenly promise global ordering, which would severely limit scalability.
Metadata management and partition leadership
Each partition is typically owned by a leader broker responsible for handling reads and writes. Metadata services track which broker is responsible for which partition. Producers and consumers consult this metadata to route requests efficiently.
Explaining leader ownership sets the stage for later discussions about replication and failover.
Message persistence, retention, and replay
Unlike transient message queues, most modern pub-sub systems are designed as durable event logs. Persistence allows consumers to process messages asynchronously, recover from failures, and replay history. Interviewers expect candidates to articulate that durability is not just about preventing data loss, but about enabling decoupled consumption and recovery.
A strong answer emphasizes that persistence semantics define how producers and consumers reason about correctness and fault tolerance.
Log-structured storage model
Most scalable pub-sub systems use a log-structured storage model. Messages are appended sequentially to partition logs, which are stored on disk. Sequential writes maximize disk throughput and simplify indexing. Reads are also sequential, which is efficient for consumers processing streams.
In interviews, it is important to explain that random access is rare and usually limited to seeking to offsets during replay or recovery.
Segmentation, indexing, and cleanup
Partition logs are typically divided into segments to make retention and cleanup manageable. Each segment contains a contiguous range of messages. Lightweight indexes map offsets or timestamps to segment locations, enabling efficient seeks.
Retention policies determine when old segments are deleted or compacted. Time-based retention keeps messages for a fixed duration, while size-based retention caps disk usage. Some systems support log compaction, retaining only the latest message per key.
Explaining these mechanisms shows that you understand how storage scales over time.
Replay and recovery use cases
Replay allows new consumers to bootstrap state or existing consumers to recover after failure. Because messages are stored durably, consumers can reprocess events deterministically.
In interviews, it is valuable to mention that replay capability is a key reason pub-sub systems are used for event sourcing and stream processing.
Durability versus latency trade-offs
Persisting messages before acknowledging producers increases durability but adds latency. Some systems allow producers to choose acknowledgment levels, trading off speed for safety.
Interviewers often look for candidates who can articulate why durability guarantees should be configurable rather than fixed.
Consumer model, offsets, and acknowledgments
Consumers subscribe to topics and read messages independently. Consumer groups allow multiple consumers to share the load of a topic by dividing partitions among group members. Each partition is consumed by at most one consumer in a group at a time.
In interviews, it is important to emphasize that consumer groups provide parallelism without duplication within the group, while still allowing multiple groups to consume the same topic independently.
Offsets as the source of truth for the consumption state
Offsets represent a consumer’s position within a partition log. Rather than deleting messages after consumption, the system tracks offsets externally. This design allows consumers to move forward, pause, rewind, or replay without affecting others.
A strong answer explains that offsets are typically stored in a durable metadata store and committed periodically rather than after every message to balance performance and recovery accuracy.
Acknowledgment models and delivery guarantees
Acknowledgments determine when offsets are advanced. If a consumer commits an offset after processing a message, the system assumes the message has been handled. If the consumer crashes before committing, the message will be re-delivered.
This leads naturally to at-least-once delivery, which is common in pub sub systems. Interviewers expect candidates to recognize that duplicates are possible and must be handled by consumers.
Rebalancing and membership changes
When consumers join or leave a group, partitions must be reassigned. This process is called rebalancing. During rebalancing, consumption may pause briefly to ensure correctness.
In interviews, it is valuable to mention that excessive rebalancing can harm throughput and that modern designs aim to minimize disruption by using incremental or cooperative rebalancing strategies.
Designing idempotent consumers
Because duplicates are possible, consumers should be idempotent. This may involve deduplication using message IDs or designing downstream operations to tolerate repeated execution.
Explaining idempotency at the consumer level shows that you understand end-to-end correctness, not just broker behavior.
Ordering guarantees and delivery semantics
Ordering is one of the most misunderstood aspects of pub-sub systems. Most systems guarantee ordering only within a partition, not across the entire topic. This limitation enables horizontal scaling.
In interviews, clearly stating that global ordering is avoided because it would serialize all traffic is an important correctness signal.
Key-based ordering and use cases
Key-based partitioning ensures that all messages with the same key are routed to the same partition. This preserves order for related events, such as updates to the same entity.
Interviewers often probe whether candidates understand that ordering is a property of partitioning, not of the topic as a whole.
Delivery semantics and their implementation
At-most-once delivery drops messages on failure but avoids duplicates. At-least-once delivery ensures delivery but allows duplicates. Exactly-once delivery aims to guarantee one-time processing, but is complex and usually limited in scope.
A strong answer explains that exactly-once semantics are often implemented by combining idempotent producers, transactional writes, and idempotent consumers, rather than by the messaging system alone.
“Effectively once” in practice
In practice, many systems aim for “effectively once” behavior, where duplicates are rare or harmless due to idempotent processing. Interviewers value candidates who acknowledge that theoretical guarantees differ from practical outcomes.
Explaining this nuance demonstrates maturity and realism.
Backpressure, flow control, and slow consumers
In pub-sub systems, producers and consumers operate at independent speeds. If consumers fall behind, the system must absorb the imbalance without collapsing. Backpressure is the mechanism that prevents overload and resource exhaustion.
Interviewers often use this section to test whether candidates understand system stability under stress.
Pull-based versus push-based consumption
Most high-throughput pub sub systems use a pull-based model, where consumers request messages at their own pace. This naturally implements backpressure, because slow consumers simply pull less data.
Push-based systems must implement explicit flow control to avoid overwhelming consumers. Explaining why pull-based designs scale better is a strong interview signal.
Consumer lag tracking and visibility
Consumer lag measures how far behind a consumer is relative to the latest message. Tracking lag is critical for detecting slow consumers, capacity issues, or downstream failures.
In interviews, mentioning lag as a first-class metric shows operational awareness.
Buffering, quotas, and rate limiting
Brokers buffer messages for slow consumers up to retention limits. To prevent unbounded resource usage, systems often enforce quotas on producers and consumers. Rate limiting ensures that no single client monopolizes broker resources.
Explaining how quotas protect multi-tenant systems demonstrates realistic design thinking.
Handling pathological cases
In extreme cases, consumers may never catch up. The system must decide whether to drop messages, extend retention, or block producers. These decisions depend on use case and SLAs.
Interviewers appreciate candidates who acknowledge that trade-offs must be made explicitly rather than avoided.
Reliability, replication, and failover
A pub-sub system is often a system of record for events that downstream systems depend on. Losing messages can corrupt the state across many consumers. Replication ensures durability and availability even when individual brokers fail. Interviewers expect you to explain not just that replication exists, but how it preserves correctness.
A strong answer frames replication as a consensus and coordination problem, not a simple data copy.
Leader–follower replication at the partition level
Each partition is typically replicated across multiple brokers. One broker acts as the leader for that partition and handles all writes, and most reads. Followers replicate the leader’s log. This model simplifies ordering guarantees because all writes are serialized by the leader.
In interviews, it is important to state that replication happens at the partition level, not across the entire topic, which allows the system to scale horizontally.
Acknowledgment levels and durability trade-offs
Producers can often choose how many replicas must acknowledge a write before it is considered successful. Waiting for a quorum improves durability but increases latency. Acknowledging after only the leader writes improves latency but risks data loss if the leader fails.
Interviewers often probe this trade-off. A strong answer explains why different applications may choose different acknowledgment levels.
Handling broker failures and leader election
When a leader broker fails, the system must elect a new leader from the replicas that are sufficiently up to date. This election must avoid split-brain scenarios where two brokers believe they are leaders.
Explaining how the system prevents stale replicas from becoming leaders shows an understanding of correctness over availability.
Consistency during failover
During failover, some messages may be temporarily unavailable, but the system must ensure that committed messages are not lost or reordered. This may require pausing writes briefly to re-establish leadership.
Interviewers value candidates who explicitly prioritize correctness during failover rather than optimistic availability.
Scaling, multi-tenancy, and multi-region architecture
Scaling a pub-sub system involves adding brokers and increasing partition counts. More partitions allow higher throughput and more consumer parallelism, but also increase metadata overhead and rebalancing complexity.
A strong answer explains that partition count is a long-lived decision and often cannot be changed easily without operational cost.
Multi-tenant isolation and noisy-neighbor protection
In shared pub sub systems, multiple teams or applications publish and consume messages. Without isolation, a single noisy tenant can degrade performance for others. Quotas, rate limits, and per-tenant partition allocation help enforce fairness.
Interviewers often look for explicit acknowledgment of multi-tenant risks and protections.
Capacity planning and hot partition avoidance
Uneven key distribution can cause hot partitions, where a single partition receives disproportionate traffic. This limits throughput and increases latency. Strategies such as key salting, adaptive partitioning, or producer-side load awareness help mitigate this.
Discussing hot partitions signals real-world operational experience.
Multi-region replication strategies
For global systems, pub-sub platforms may replicate data across regions. Active-passive designs simplify consistency but increase failover latency. Active-active designs improve availability but complicate ordering and duplication semantics.
In interviews, explaining that many systems choose region-local consumption with asynchronous cross-region replication demonstrates pragmatic design thinking.
Consumer locality and data gravity
Consumers are often deployed near the data they consume. Designing for region-local reads reduces latency and bandwidth costs. Cross-region consumption is typically reserved for disaster recovery or analytics.
Interviewers appreciate candidates who connect architecture to network and cost realities.
Security, authorization, and operational controls
Producers and consumers must authenticate before interacting with the system. Authentication mechanisms may include API keys, OAuth tokens, or mutual TLS. Strong authentication prevents unauthorized publishing or consumption.
In interviews, it is important to separate authentication from authorization and explain their distinct roles.
Authorization at topic and subscription levels
Authorization controls who can publish to or subscribe from specific topics. Fine-grained permissions reduce blast radius and support multi-tenant isolation. Authorization decisions are typically enforced by brokers on every request.
Explaining authorization as a core broker responsibility shows attention to security boundaries.
Encryption and data protection
Messages often contain sensitive data. Encryption in transit protects data on the network, while encryption at rest protects persisted logs. Key management and rotation are critical operational concerns.
Interviewers value candidates who recognize that pub sub systems are often part of compliance-sensitive pipelines.
Schema governance and compatibility
Many pub sub systems integrate with schema registries to enforce message structure and compatibility rules. This prevents producers from breaking consumers by changing message formats unexpectedly.
Discussing schema evolution shows awareness of long-term system maintainability.
Operational safeguards and safe configuration changes
Operational controls include limits on topic creation, retention enforcement, and staged configuration rollouts. These safeguards prevent accidental misuse or catastrophic misconfiguration.
In interviews, highlighting operational guardrails demonstrates maturity beyond theoretical design.
Observability, cost considerations, and interview wrap-up with trade-offs
Operating a pub sub system without observability is nearly impossible. Metrics such as publish latency, end-to-end latency, throughput, consumer lag, replication health, and disk utilization are essential.
A strong answer explains how these metrics inform scaling, troubleshooting, and capacity planning.
Logging, tracing, and debugging distributed flows
Distributed tracing helps follow messages from producers through brokers to consumers. Structured logs enable root cause analysis when things go wrong.
Interviewers often appreciate candidates who connect observability to faster recovery and lower operational risk.
Cost drivers in pub sub systems
Storage retention, replication factor, and cross-region traffic are major cost drivers. Higher durability and longer retention increase cost. Efficient batching and compression reduce network usage.
Explaining cost trade-offs demonstrates that you design systems with economic constraints in mind.
Key trade-offs to articulate in interviews
Pub-sub System Design involves constant trade-offs. Strong durability increases latency. Strict ordering limits throughput. Exactly-once semantics add complexity. Simpler designs are easier to operate but less flexible.
Explicitly naming these trade-offs and justifying choices is often what distinguishes senior candidates.
How to present this design under time pressure
In time-limited interviews, focus on partitions, persistence, delivery semantics, and failure handling. These areas best demonstrate distributed systems understanding. Avoid getting lost in API details unless prompted.
Showing that you can prioritize the right topics is itself an interview skill.
Using structured prep resources effectively
Use Grokking the System Design Interview on Educative to learn curated patterns and practice full System Design problems step by step. It’s one of the most effective resources for building repeatable System Design intuition.
You can also choose the best System Design study material based on your experience:
Final thoughts
Designing a pub-sub system is about enabling decoupled systems to communicate reliably under constant change and failure. Interviewers use this question to test whether you can reason about throughput, correctness, and resilience simultaneously.
Strong answers emphasize clear guarantees, thoughtful partitioning, durable storage, and realistic failure handling. They acknowledge that no system can optimize all dimensions at once and that trade-offs must be explicit.
If you structure your explanation clearly, state assumptions up front, and anchor decisions in real-world constraints, pub sub System Design becomes an opportunity to showcase deep distributed systems thinking rather than an abstract theoretical exercise.
