If you have ever shared a long, ugly URL and wished it were shorter, you have already used the idea behind TinyURL or Bitly. These systems look simple on the surface: you give them a long link, and they return a compact version that is easier to share. But under that simplicity sits a design problem that shows up again and again in backend engineering and in interviews. It is a great exercise because it touches storage, scalability, caching, reliability, and API design without requiring a massive product surface.
That is exactly why this is such a popular interview question. A good interviewer is not trying to see whether you can memorize one perfect answer. They want to see whether you can start with a small product idea, identify the right requirements, and then evolve the design as scale and complexity increase. In other words, this is less about remembering a diagram and more about showing structured reasoning.
In this walkthrough, we will go through a full Tiny URL system design discussion the way you would in a serious interview. We will start with the problem, define requirements, design a simple solution, and then gradually improve it for scale and resilience. Along the way, we will focus on trade-offs instead of pretending there is only one correct architecture. That is the habit that makes you stronger in system design interviews.
Understanding the problem and requirements
At the product level, the system has two core jobs. First, it should accept a long URL and generate a much shorter alias that maps back to the original. Second, when a user visits that short URL, the system should redirect them quickly and reliably to the original destination. If you stop there, you already have enough for a basic design. But interviews rarely stop there, because the real value comes from exploring what happens when traffic increases or product features expand.
To make the discussion concrete, you should separate functional requirements from non-functional requirements. Functionally, the system must create short URLs, store mappings, and redirect users correctly. It may also support optional features such as custom aliases, expiration, analytics, or duplicate detection. Non-functionally, the system should offer low-latency reads, high availability, and enough scalability to support a large number of redirects. Since short-link systems are usually read-heavy, the design should prioritize very fast lookup performance.
It also helps to state a few assumptions early. For example, you can assume that redirects are far more frequent than new URL creations, which means reads dominate writes. You can also assume that the short code should be unique, compact, and safe to include in URLs. Finally, you can state that strong consistency for every read may not be necessary if the system favors availability and low latency, especially at scale. Interviewers usually like when you make these assumptions explicit instead of hiding them.
High-level design overview
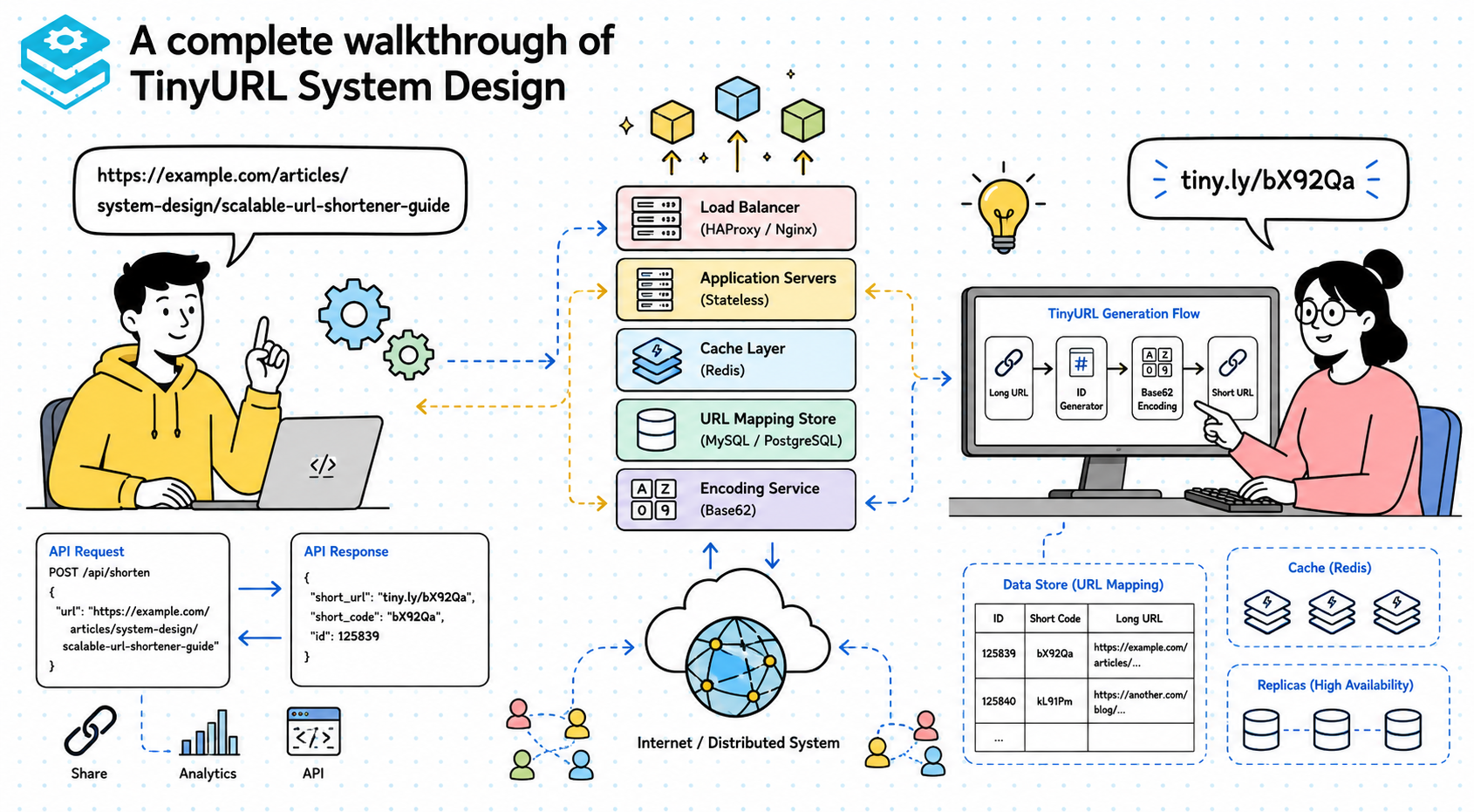
At a high level, the system can be broken into a few clear components. You need an API layer to accept create and redirect requests, an encoding or ID-generation mechanism to produce short codes, and a storage layer to persist the mapping between short and long URLs. In a simple version, this can all be handled by a small backend service and a database. The point is not to start with a complex architecture, but to build something minimal that actually solves the problem.
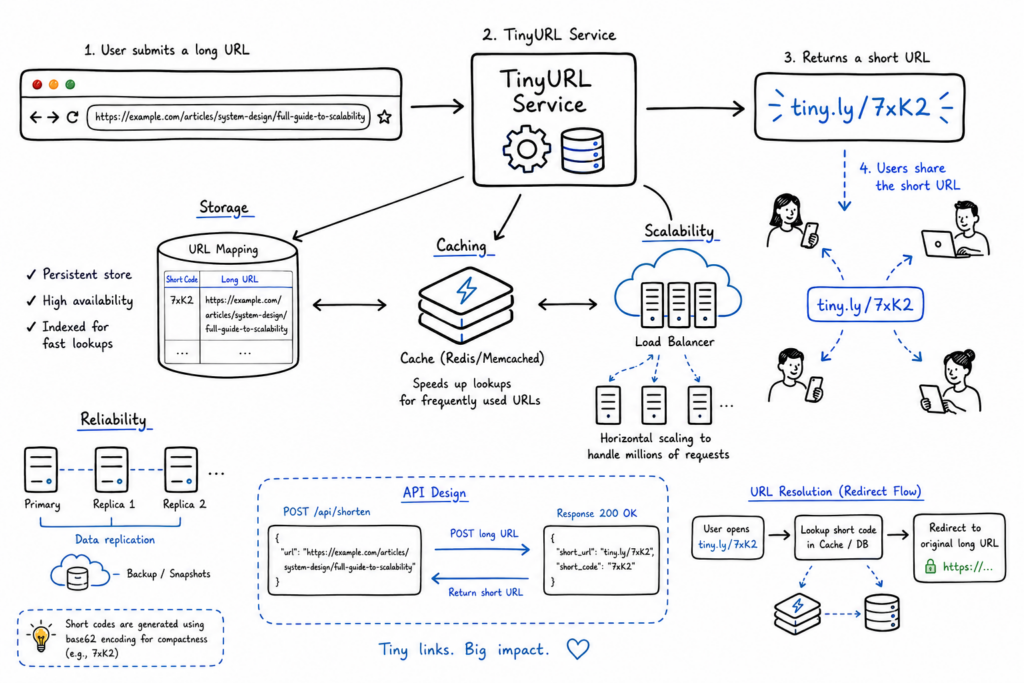
The creation flow is straightforward. A client sends a long URL to the shortening API, the service generates a unique short identifier, stores the mapping, and returns the shortened link. The redirect flow is even simpler. A client requests the short URL, the backend looks up the original URL in storage, and the service returns an HTTP redirect response. That is already enough to show the core logic of the system without getting lost in premature optimization.
What matters in an interview is that you narrate the request flow clearly. If your explanation jumps straight into Redis clusters and sharding before the base flow is understood, the design can feel disconnected. A strong answer starts simple, proves the system works, and then scales that design only when the requirements justify it. That sequence makes your reasoning much easier to follow.
Reframing the Tiny URL system design around ID generation
The most interesting part of this problem is not the API endpoint. It is how you generate short codes reliably and efficiently. This is where a lot of candidates jump to “just hash the URL,” but that answer needs more care. Hashing looks attractive because the same URL always produces the same result, which can help with duplicate detection. But a raw hash is too long, and truncating it introduces collision risk unless you manage it carefully.
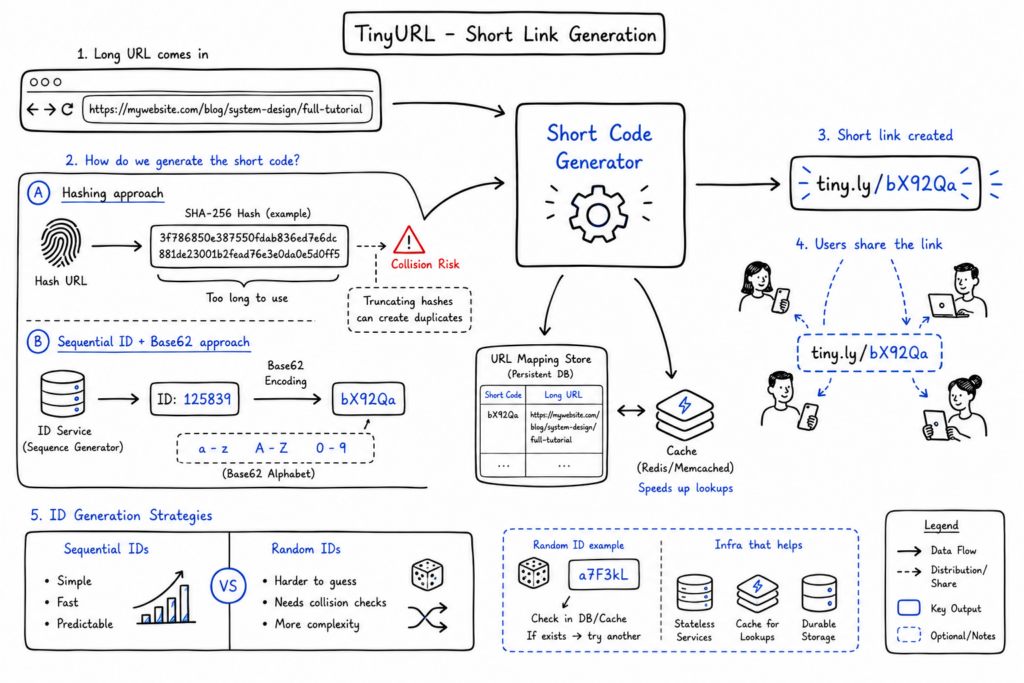
A more practical approach is to generate a unique numeric ID and then encode it into a URL-friendly alphabet. Base62 encoding is a common choice because it uses lowercase letters, uppercase letters, and digits, which gives you 62 possible characters at each position. This lets you represent a large number of IDs in a very short string. For example, an auto-incrementing ID from a database or an ID service can be transformed into a compact short code without exposing a huge integer directly.
You could also use random string generation instead of sequential IDs. That avoids predictable link patterns and may feel more secure from a product perspective. However, randomness creates its own challenges because you must check for collisions and ensure uniqueness before returning the code. Sequential IDs plus encoding are operationally simpler, while random IDs give better obscurity but introduce more write-path complexity. In an interview, the important thing is to explain why you choose one and what trade-off you accept.
Designing the URL shortening logic
If you choose an ID-based approach, the create flow becomes elegant. The system first obtains a unique ID, either from the primary database, a sequence generator, or a dedicated ID service. It then converts that ID into a Base62 string and stores the mapping from short code to long URL. The response returned to the client is simply the service domain plus that encoded string. This works well because the lookup path is direct and the generated code stays short.
Collision handling depends on the generation strategy. With sequential IDs, collisions are effectively avoided because uniqueness is guaranteed before encoding. With random IDs or truncated hashes, you need an existence check before finalizing the short code. If the generated code already exists, you retry or extend the code length. This is manageable, but it means your write path is a bit more expensive and operationally less predictable.
There is also the question of duplicate long URLs. Should the same long URL always map to the same short code, or should each request generate a fresh one? A simple system can treat each shorten request as a new record, which is easy to implement and keeps the write path simple. A smarter system might normalize the URL and check for an existing mapping to avoid duplicate entries. That reduces storage usage, but adds lookup overhead and introduces edge cases around tracking, expiration, or custom aliases. In practice, whether you deduplicate depends on product goals more than raw engineering preference.
Database design and storage strategy
The storage model for this system is naturally key-value shaped. The short code acts as the key, and the value contains the original URL plus optional metadata such as creation timestamp, expiration time, creator ID, or click count. This makes the read path very efficient because redirect requests are essentially point lookups. Since the dominant operation is “given this short code, find the original URL,” the schema should be optimized for exactly that access pattern.
A relational database can work perfectly well at small or moderate scale, especially if you want strong indexing and transaction support. For example, a SQL table with short_code, long_url, created_at, and expires_at is easy to reason about and easy to manage early on. But if the system grows into billions of mappings with extremely high read throughput, a distributed NoSQL or key-value store becomes more attractive. Systems like DynamoDB, Cassandra, or a similar distributed store fit read-heavy patterns well, especially when low-latency lookups are essential.
This is one of those interview moments where balance matters. You do not want to declare SQL outdated or pretend NoSQL is always better. SQL is often the fastest path to a correct initial solution. NoSQL becomes compelling when scalability, partitioning, and high-throughput access patterns start to dominate the design. A strong answer explains the access pattern first and then chooses the storage model that best fits it.
Scaling the system for high traffic
Once traffic grows, the redirect path becomes the real scaling challenge. This system is read-heavy, so you want to optimize for very fast and very frequent lookups. Horizontal scaling at the API layer is straightforward: run multiple stateless application servers behind a load balancer. That lets the system absorb incoming traffic spikes without relying on a single machine. Since the application servers do not keep important session state, they are easy to replicate.
Caching becomes a major optimization at this stage. Popular links may be requested repeatedly, and hitting the database every time is wasteful. A distributed cache like Redis can store the short-code-to-long-URL mapping for hot entries, significantly reducing database load and improving latency. The redirect flow then becomes: check cache first, fall back to database if needed, and refresh cache on a miss. In a large-scale system, this one decision can make a dramatic difference in performance.
To support millions of requests, you may also need sharding or partitioning in the storage layer. Sequential ID generation can create hotspots if all recent writes land on one database partition, so the storage strategy has to be chosen carefully. Read replicas, partition-aware key design, and regional traffic distribution may all become part of the solution. The key is to scale in layers: stateless API servers, aggressive caching, then storage partitioning when the access pattern demands it.
Comparing design maturity levels
| Design level | Complexity | Performance | Scalability | Cost |
| Simple design | Low | Good for small workloads | Limited | Low |
| Moderately scalable design | Medium | Strong with caching | Handles substantial traffic | Moderate |
| Highly scalable production design | High | Excellent under heavy load | Designed for massive scale | High |
A simple design is often enough for an interview starting point. A single backend service with a relational database can absolutely handle the core use case and demonstrates that you understand the basics. This version is easy to explain, cheap to run, and perfectly reasonable if the product is small or internal. The main limitation is that it will eventually struggle with very high read volumes and geographic distribution.
A moderately scalable design usually adds horizontal application scaling, a cache layer, and a more deliberate storage model. This is often the sweet spot for a realistic interview answer because it shows that you can identify the main bottlenecks without overengineering the system. A highly scalable production design might introduce sharded storage, multi-region routing, advanced observability, background analytics pipelines, and stronger resilience patterns. That version is useful to discuss once the interviewer asks how you would handle very large scale, but it should grow naturally from the simpler design rather than appearing all at once.
Handling edge cases and failures
Real systems are defined by how they behave when things go wrong, not just when everything works. Expired links are a simple but important example. If a user requests a short URL that has passed its expiration time, the system should not blindly redirect. Instead, it should return a controlled response, such as a 404 or a dedicated “link expired” page, depending on product expectations. This means expiration logic needs to be checked on the redirect path, not just stored as metadata.
Broken links are another unavoidable case. The original long URL may no longer exist, but from the shortener’s perspective, the mapping is still valid. In most designs, the shortener should still redirect because it is not responsible for the health of the destination site. However, if analytics or abuse control matter, you may want background systems that detect repeated destination failures and flag suspicious or dead links for review.
Duplicate URLs create a product-level decision rather than a correctness problem. If two users shorten the same link, should they get the same short code? Sometimes yes, because it reduces storage duplication. Sometimes no, because separate short codes enable independent analytics, ownership, or expiration policies. There is no universal answer, which makes it a good interview discussion point. What matters is that you recognize the trade-off instead of assuming one behavior is obviously correct.
Trade-offs in design decisions
This problem is full of classic design trade-offs. Consistency versus availability is one of the most obvious. If a new short URL is created and the system is highly distributed, do you require every region to agree immediately before serving it everywhere? That increases consistency but can hurt latency and availability. In many real systems, eventual consistency is acceptable because the main requirement is fast redirect behavior, not strong multi-region synchronization for every write.
Storage versus performance is another trade-off that appears quickly. Keeping every mapping in a cache would improve read latency, but caching everything is expensive and often unnecessary. Caching only hot links is more efficient, but requires good eviction strategy and acceptance that cold reads will hit the database. Similarly, deduplicating URLs can reduce storage use, but adds complexity and may conflict with analytics needs. Every optimization has a cost somewhere else in the system.
Simplicity versus scalability is perhaps the most important interview theme. A very simple design is easy to build, easy to reason about, and often good enough early on. But as requirements grow, simplicity alone is not enough. The strong candidate does not start with the most scalable architecture possible. Instead, they begin with a simple version and explain exactly when and why additional complexity becomes necessary. That progression shows judgment, which is what interviewers care about.
Enhancements and advanced features
Custom aliases are a natural product enhancement. Instead of assigning only system-generated short codes, you can let users choose a readable alias like /summer-sale or /portfolio. This sounds easy, but it introduces uniqueness checks, abuse prevention, reserved keyword handling, and sometimes pricing or ownership rules. The feature changes the write path because user input now affects key generation, and the system must validate that alias carefully.
Analytics is another common enhancement in real URL shorteners. Once you care about click counts, geography, referrer data, or device information, the redirect path becomes more than a simple lookup. You usually do not want to slow down redirects by performing heavy writes synchronously, so analytics events are often pushed asynchronously to a queue or stream for later processing. This is a good example of how product features can reshape the architecture without changing the core redirect logic.
Rate limiting also becomes important in production. Malicious users could create huge numbers of links, spam custom aliases, or hammer redirect endpoints. Simple rate limiting at the API layer can protect the create path, while abuse detection logic may watch for suspicious redirect patterns or phishing behavior. These features are not strictly necessary in a baseline interview design, but mentioning them shows that you understand how real systems evolve beyond the happy path.
How this appears in interviews
Clarifying requirements first matters because the same TinyURL-style system can look very different depending on scale, analytics needs, expiration rules, or whether custom aliases are required. If you skip that conversation, you risk solving the wrong problem very elegantly. Interviewers usually reward candidates who slow down just enough to define the problem before designing. It shows discipline and keeps the discussion grounded.
Starting with a simple design is equally important. If you immediately introduce distributed ID generators, global replication, and multiple cache tiers, you make the answer harder to follow and often less convincing. A simple design proves you understand the core mechanics first. Scaling step by step then shows that you can evolve the architecture in response to traffic and reliability needs rather than treating system design as a bag of advanced buzzwords.
Conclusion
A good tiny URL system design answer is not about producing a perfect diagram from memory. It is about showing how you think: how you define requirements, choose data models, reason about ID generation, and scale the system when traffic grows. The interviewer is usually more interested in your structure and trade-off analysis than in whether your cache choice matches their personal preference.
If you practice this problem the right way, you get much more than one interview answer. You build the habit of moving from product requirements to architecture, then from architecture to constraints, and finally from constraints to scaling decisions. That habit applies to many other design problems beyond URL shorteners. Keep practicing with the same level of structured reasoning, and your confidence in system design interviews will grow quickly.
Happy learning!
