
System Design interviews are a distinct challenge in software engineering. A skilled coder with strong algorithmic abilities can still find it difficult to architect a scalable solution for a service like Instagram. These interviews test your ability to manage complexity, navigate ambiguity, and balance competing constraints. They assess how you make high-stakes technical decisions that determine if a system scales or degrades under load.
The objective is to demonstrate a structured reasoning process. Interviewers look for engineers who understand that every architectural choice has a cost, from database selection to communication protocols. This guide provides a framework for thinking like a senior architect.

These interconnected pillars form the basis for all architectural decisions, requiring engineers to understand how each choice ripples through the system.
The foundation of System Design
Before reviewing specific technologies, it is important to shift from an implementation mindset to an architectural one. Coding interviews focus on the efficiency of an algorithm. System Design requires a broad view of how components interact, fail, and evolve. You are designing an ecosystem that must support millions of users while remaining cost-effective and resilient.
To perform well, visualize the system in logical layers. The client layer handles user interaction through mobile apps or web interfaces and communicates through API gateways. The application layer contains the business logic and microservices that process requests. The data layer manages persistence using databases, caches, and object storage.
A critical early decision is choosing an architectural style. You must decide between a monolithic architecture, where all components are coupled in a single codebase, and a microservices architecture, with decoupled, independently deployable services. Monoliths are simpler to deploy initially, but microservices can offer better scalability and fault isolation when designed correctly. Serverless architectures have also gained traction, though they can introduce cold start latency trade-offs.
With a structural foundation in place, the next challenge is ensuring the system can handle growth.
Scalability
Scalability measures a system’s ability to handle an increased load without performance degradation. A system must not only work today but also support ten times the load tomorrow. This includes more users, higher data volume, or increased transaction rates.
There are two primary approaches to scaling. Vertical scaling (scale-up) involves adding more power (CPU and RAM) to a single machine. It is simple but has a hard limit and creates a single point of failure. Horizontal scaling (scale out) is preferred for distributed systems, where you add more machines to a pool. To manage this distribution, you use load balancing to distribute traffic across servers using algorithms like round-robin or least-connections.
The distinction between these two scaling strategies becomes clearer when visualized side by side.

Scaling out introduces data complexity. When a single database cannot handle the load, you must use sharding (horizontal partitioning) to split data across multiple nodes based on a shard key. To ensure data is evenly distributed and minimize reorganization when nodes change, use Consistent Hashing. This technique maps both data and servers to a ring, so adding a server only requires moving a small fraction of keys.
Scalability helps you handle traffic. Reliability ensures that traffic is served successfully even in the event of failures.
Reliability and fault tolerance
In distributed systems, failure is a statistical certainty. Components like hard drives and networks will fail, and new code can introduce bugs. A reliable system is designed to function correctly even when its underlying components are failing.
To achieve this, design for redundancy and graceful degradation. Replication ensures data is stored across multiple servers or regions, preventing data loss if a primary node fails. Failover mechanisms automatically detect these failures and redirect traffic to healthy standby instances. If a service is slow, it can cause a cascade of failures across the system.
Engineers use the circuit breaker pattern to mitigate this cascading effect. This component detects when a downstream service is failing and temporarily blocks access, returning an immediate error or a fallback. This gives the failing service time to recover. Similarly, the bulkhead pattern isolates application elements into pools so that if one fails, the others continue to function.
Designing for reliability often requires making difficult choices between data accuracy and system availability.
Trade-offs between availability, consistency, and partition tolerance
A key concept in System Design is the CAPConsistency, Availability, Partition Tolerance theorem. It states that a distributed data store can only provide two of the following three guarantees at once. Consistency means every read receives the most recent write or an error. Availability means every request receives a non-error response. Partition tolerance means the system continues to operate despite network failures.
Since network partitions are unavoidable, you must often choose between Consistency (CP) and Availability (AP). Banking systems typically choose CP using ACIDAtomicity, Consistency, Isolation, Durability transactions because showing an incorrect balance is unacceptable. Social media feeds often favor AP and use eventual consistency with a BASEBasically Available, Soft state, Eventual consistency model. It is acceptable if one user sees a post a few seconds later than another, as long as the feed loads quickly.
The CAP theorem is sometimes considered too simplistic. A more nuanced framework is the PACELCPartition, Availability, Consistency Else Latency, Consistency theorem. It states that even without a partition, a system must choose between Latency (L) and Consistency (C). Strong consistency requires replicating data to all nodes before confirming a write, which increases latency. Low latency might mean accepting that some nodes have stale data.
To better understand how these theoretical constraints translate into practical architectural decisions, consider how different systems prioritize these guarantees.

This framework guides consistency decisions, but the practical impact of these choices becomes most visible when examining how quickly systems respond to user requests.
After determining the required level of consistency, the focus shifts to performance.
Performance and latency optimization
Performance is a primary driver of user retention. A reliable system that takes five seconds to load a page is not useful to a user. Optimization requires a focus on reducing latency and increasing throughput.
Caching is the most effective tool for improving performance. Storing frequently accessed data in memory (e.g., Redis or Memcached) or closer to the user via content delivery networks (CDNs) significantly reduces retrieval times. You must also consider read vs. write optimization. Read-heavy systems might use denormalized databases or read replicas. Write-heavy systems often use asynchronous processing with message queues like Kafka to buffer writes and smooth traffic spikes.
Database performance can be tuned using indexing, which speeds up data retrieval at the cost of slower writes. Optimizing network traffic through batching (grouping requests) and compression reduces the payload size, which is critical for mobile users on unstable networks.
A complete request flow demonstrates how these optimization techniques work together to reduce latency.

While performance optimization improves user experience, it creates new vulnerabilities that must be addressed through comprehensive security measures.
Security and data protection in System Design
Security should be integrated from the start of the design process. It is a fundamental constraint that shapes the architecture. In a System Design interview, demonstrating this understanding can distinguish a senior engineer from a junior one.
A strong security posture begins at the entry point with the API gateway pattern. The gateway acts as a single entry point, handling authentication (verifying the user via OAuth 2.0 or JSON Web Token (JWT)) and authorization (verifying permitted actions). It also enforces rate limiting to prevent many denial-of-service (DoS) and abuse scenarios. Internally, you should apply the principle of least privilege, ensuring that services and users have only the permissions necessary to perform their functions.
The layered approach to securing a distributed system can be understood through the flow of authenticated requests.

Data protection extends to storage and transmission. Ensure encryption in transit (using TLS/SSL) so data cannot be intercepted between the client and server. Use encryption at rest (using Advanced Encryption Standard (AES)) to protect data on disks. All user input must undergo rigorous input validation to prevent common exploits such as SQL injection and cross-site scripting (XSS).
After securing and optimizing the system, the final step is ensuring long-term maintainability.
Observability, monitoring, and maintainability
Modern distributed systems involve complex microservice interactions, making debugging difficult without proper visibility. Observability allows you to understand a system’s internal state from its external outputs.
Observability relies on three pillars. Metrics are quantitative data like CPU usage, latency, and error rates. Logs are discrete events and error messages. Traces show the path of a request as it moves between microservices. Tools like Prometheus, Grafana, and OpenTelemetry are standard for this. In microservices architectures, distributed tracing is essential for pinpointing which service is causing a performance constraint.
Understanding how these components interconnect is essential for building effective monitoring strategies.
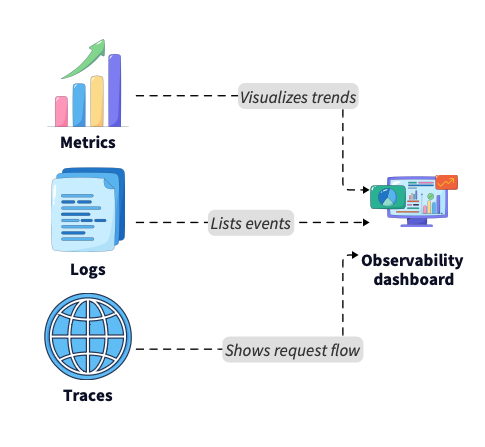
These observability components provide the visibility needed to maintain complex systems, enabling engineers to track how operations flow across distributed architectures.
Maintainability also involves managing transactions across services. The saga pattern is a crucial design concept for this. Since distributed transactions are difficult, Sagas break a transaction into a sequence of smaller, local transactions. If one step fails, the Saga executes compensating transactions to undo previous changes, ensuring data integrity without locking the system.
Understanding these principles is the first step. Applying them effectively in an interview is the next step.
Applying System Design principles in interviews
Strong System Design interviews follow a structured approach. You must drive the conversation by explaining your design choices.
Follow a five-step framework:
- Clarify the problem: Ask questions to determine the scope, such as “How many daily active users?” and “Do we need real-time updates?”
- Define the scope: Agree on the Minimum Viable Product (MVP). Avoid designing every feature of a large application in 45 minutes.
- Sketch the architecture: Draw the high-level components, including the Client, API Gateway, Load Balancer, Services, and Database.
- Deep dive and trade-offs: Pick a complex component and apply the principles to it. Explain why you chose a NoSQL database over SQL (e.g., “We need a flexible schema and high write throughput”).
- Iterate and improve: Identify performance constraints in your own design. For example, “This database is a single point of failure, so I would add a read replica.”
Managing your time effectively across these phases is crucial for demonstrating comprehensive architectural thinking.

Following this structured timeline helps candidates demonstrate their architectural thinking while ensuring they address all critical design aspects within the available time.
Conclusion
Mastering System Design means understanding trade-offs. Scalability requires complexity, reliability requires redundancy, and performance often requires sacrificing strict consistency.
As systems evolve, new paradigms like serverless computing and edge processing introduce new considerations. The core principles, however, remain unchanged. The ability to reason through constraints is what defines a senior engineer, whether you are building a monolith or a distributed mesh of microservices.
Internalize the logic behind these principles instead of just memorizing the terms. When you can explain why a circuit breaker protects a system during a traffic spike or why eventual consistency is acceptable for a “Like” counter, you are better prepared for your interview and for building robust systems. In interviews, the ability to reason clearly under constraints is often as important as the final architecture you draw.
