Primary Key vs. Foreign Key: A Complete Guide For Database Design And Interviews
When you start designing relational databases, one of the first real challenges you encounter is defining how data connects across tables. At that point, primary keys and foreign keys stop being abstract concepts and become the foundation of your entire schema. If you get them right, your system remains clean, scalable, and reliable, but if you get them wrong, issues start surfacing in unexpected ways.
Many engineers initially treat keys as simple constraints added to satisfy database rules. However, in real-world systems, keys define how data flows, how relationships are enforced, and how queries are executed efficiently. This is why understanding primary key vs foreign key is not just important for interviews, but essential for building systems that scale.
Why Keys Matter More Than You Expect
In any non-trivial application, your database is not just storing isolated records. It is managing relationships between users, orders, messages, and countless other entities. Primary and foreign keys act as the glue that holds this structure together, ensuring that every piece of data has a clear identity and a valid connection.
Without properly defined keys, your database quickly becomes inconsistent and difficult to manage. You may end up with duplicate records, broken relationships, or queries that return unreliable results. These are not theoretical problems, but common issues seen in poorly designed systems.
From Simple Constraints To System Design Foundations
As you move toward System Design thinking, you will realize that keys influence much more than data integrity. They impact indexing strategies, query performance, and even how your system scales across multiple nodes. This is why experienced engineers think carefully about key design from the very beginning.
Throughout this guide, you will move beyond basic definitions and start understanding how primary keys and foreign keys shape real-world database architectures. This shift in perspective is what allows you to design systems that are both efficient and maintainable.
What Is A Primary Key (Concept And Purpose)
A primary key is the most fundamental concept in relational databases, yet it is often misunderstood as just a technical requirement. At its core, a primary key is a column or set of columns that uniquely identifies each record in a table. This uniqueness ensures that every row can be referenced reliably without ambiguity.
When you think about a database table as a collection of entities, the primary key acts as the identity of each entity. Without it, the database would have no reliable way to distinguish between records, especially when dealing with large datasets.
Defining Uniqueness And Identity
The defining characteristic of a primary key is that it must be unique and cannot contain null values. This ensures that every record has a valid and distinct identity, which is critical for maintaining data integrity. In practice, this means that no two rows in a table can share the same primary key value.
This concept becomes especially important as your system grows. In large-scale systems, where millions of records are stored and accessed, having a reliable way to identify each record is essential. Without this, operations such as updates and deletions become error-prone and inefficient.
Types Of Primary Keys In Practice
Primary keys can be designed in different ways depending on the system’s requirements. Some keys are derived from real-world data, while others are artificially generated. Understanding these approaches helps you make better design decisions.
| Primary Key Type | Description | Example |
|---|---|---|
| Natural Key | Derived from real-world data | Email, Social Security Number |
| Surrogate Key | Artificially generated identifier | Auto-increment ID, UUID |
Natural keys are intuitive because they represent meaningful data, but they can change over time, which introduces complexity. Surrogate keys, on the other hand, are stable and easier to manage, which is why they are commonly used in modern systems.
Why Primary Keys Influence Performance
Primary keys are automatically indexed in most relational databases, which means they play a significant role in query performance. When you query a table using its primary key, the database can locate the record quickly without scanning the entire dataset.
This efficiency becomes critical in high-traffic systems where performance is a priority. Choosing the right primary key not only ensures data integrity but also improves the speed of database operations. This is why primary key design is often discussed in System Design interviews.
What Is A Foreign Key (Concept And Purpose)
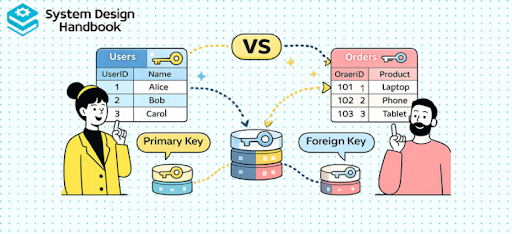
While primary keys define the identity of records within a table, foreign keys define relationships between tables. A foreign key is a column that references the primary key of another table, creating a link between two sets of data. This connection allows databases to represent real-world relationships in a structured way.
In practical terms, foreign keys enable you to connect entities such as users and orders, or posts and comments. Without these relationships, your data would exist in isolation, making it difficult to build meaningful applications.
Establishing Relationships Between Data
Foreign keys are essential for modeling relationships in relational databases. They ensure that data in one table corresponds to valid data in another table. For example, an order record can reference a user through a foreign key, ensuring that every order is associated with a valid user.
This relationship is enforced by the database, which prevents invalid references. If you attempt to insert a record with a foreign key that does not exist in the referenced table, the database will reject the operation. This helps maintain data consistency across the system.
Understanding Referential Integrity
Referential integrity is the principle that ensures relationships between tables remain valid. Foreign keys enforce this principle by restricting operations that would break these relationships. For example, deleting a user who still has associated orders may be prevented or handled in a controlled way.
This mechanism protects your data from inconsistencies and ensures that relationships remain meaningful. Without referential integrity, you could end up with orphaned records that reference non-existent entities, which can lead to incorrect application behavior.
How Foreign Keys Are Used In Real Systems
To better understand the role of foreign keys, consider a simple example of users and orders.
| Table Name | Column Name | Role |
|---|---|---|
| Users | user_id | Primary Key |
| Orders | user_id | Foreign Key |
In this setup, the Orders table uses the user_id column to reference the Users table. This creates a relationship where each order is linked to a specific user. This pattern is widely used in real-world systems to maintain structured and meaningful data relationships.
Primary Key Vs Foreign Key: Core Differences
Now that you understand primary keys and foreign keys individually, it is important to compare them directly. While they are closely related, they serve fundamentally different purposes in database design. Understanding these differences will help you use them effectively in your schemas.
At a high level, primary keys define identity, while foreign keys define relationships. This distinction may seem simple, but it has significant implications for how your database operates and scales.
Comparing Roles And Responsibilities
Primary keys and foreign keys operate at different levels within a database. A primary key is responsible for uniquely identifying records within a table, while a foreign key connects records across tables. This difference defines how they are used in queries and data modeling.
| Feature | Primary Key | Foreign Key |
|---|---|---|
| Purpose | Uniquely identifies a record | Links to another table |
| Uniqueness | Must be unique | Can have duplicate values |
| Nullability | Cannot be null | Can be null (depending on design) |
| Scope | Within a single table | Across multiple tables |
This comparison highlights that primary keys focus on internal structure, while foreign keys enable external relationships. Both are essential, but they solve different problems.
Understanding Their Interaction In Queries
In practical database operations, primary and foreign keys work together to enable efficient data retrieval. When you perform a join operation, the database uses these keys to match related records across tables. This allows you to combine data from multiple sources into a single result set.
The efficiency of these operations depends heavily on how well the keys are designed and indexed. Poorly designed keys can lead to slow queries and increased system load, especially in large datasets. This is why understanding their interaction is critical for performance optimization.
Why Both Are Essential For Relational Design
Relational databases rely on the combination of primary and foreign keys to maintain structure and consistency. Without primary keys, you lose the ability to uniquely identify records. Without foreign keys, you lose the ability to define relationships between them.
Together, they create a system where data is both organized and interconnected. This balance is what makes relational databases powerful and reliable. As you continue learning, you will see how these concepts extend into more advanced topics such as indexing, scaling, and distributed systems.
How Primary Keys Influence Database Design
As you start designing real database schemas, you quickly realize that choosing a primary key is not just a formality. It is a foundational decision that affects how your data is stored, accessed, and scaled over time. A well-designed primary key simplifies queries and improves performance, while a poorly chosen one can introduce inefficiencies that are difficult to fix later.
Primary keys influence how tables are indexed and how records are retrieved. Since most databases automatically create indexes on primary keys, they become the fastest way to access data. This means your choice of primary key directly impacts the speed of your system under load.
Choosing Between Natural And Surrogate Keys
One of the most important decisions you will make is whether to use a natural key or a surrogate key. Natural keys are derived from real-world data, such as an email address, while surrogate keys are artificially generated identifiers like auto-increment IDs or UUIDs.
Natural keys can make your data more intuitive because they carry meaning, but they can also change over time, which introduces complexity. Surrogate keys, on the other hand, are stable and consistent, making them easier to manage in large systems. This is why most production systems favor surrogate keys despite their lack of real-world meaning.
Impact On Indexing And Query Performance
Primary keys are automatically indexed, which means they are optimized for fast lookups. When you query a table using its primary key, the database can locate the record efficiently without scanning the entire dataset. This becomes increasingly important as your data grows.
However, not all primary keys perform equally well. For example, sequential IDs are easier for databases to index and store efficiently, while randomly generated UUIDs can lead to fragmentation and slower performance. Understanding these nuances helps you design systems that scale smoothly.
Primary Keys And Data Distribution
In distributed systems, primary keys play a critical role in how data is partitioned across nodes. If your primary key is not designed with distribution in mind, you may end up with uneven data distribution, which can create performance bottlenecks.
For example, sequential IDs can lead to hotspot issues where new records are always written to the same node. This is why some systems use randomized or composite keys to distribute load more evenly. These design decisions are often discussed in advanced System Design interviews.
How Foreign Keys Define Relationships Between Tables
While primary keys define identity, foreign keys define how different pieces of data relate to each other. This relationship modeling is at the core of relational database design and allows you to represent complex real-world interactions in a structured way.
Foreign keys create a connection between tables by referencing the primary key of another table. This connection ensures that related data remains consistent and meaningful, which is essential for building reliable applications.
Understanding One-To-One And One-To-Many Relationships
In relational databases, relationships are typically categorized based on how records in one table relate to records in another. A one-to-one relationship means that each record in one table corresponds to exactly one record in another table. This is often used for splitting data into logical groups while maintaining a direct connection.
A one-to-many relationship is more common and represents scenarios where a single record is associated with multiple records in another table. For example, a single user may have multiple orders, which are stored in a separate table but linked through a foreign key. This structure allows you to organize data efficiently while maintaining clear relationships.
Modeling Many-To-Many Relationships
Many-to-many relationships occur when records in one table can be associated with multiple records in another table, and vice versa. These relationships are typically implemented using a junction table that contains foreign keys referencing both tables.
This approach allows you to represent complex relationships without duplicating data. For example, a student can enroll in multiple courses, and each course can have multiple students. A junction table ensures that these relationships are stored efficiently and can be queried easily.
Why Relationships Matter For Query Design
Foreign keys are not just about enforcing constraints; they also play a critical role in query design. When you perform joins between tables, the database uses these keys to match related records. This allows you to retrieve connected data in a structured and efficient way.
However, as the number of relationships increases, queries can become more complex and resource-intensive. This is why designing relationships carefully is essential for maintaining both performance and readability in your database queries.
Referential Integrity And Data Consistency
Referential integrity is one of the most important concepts in relational databases, and it is enforced through foreign key constraints. It ensures that relationships between tables remain valid and that data does not become inconsistent over time. Without it, your database can quickly accumulate errors that are difficult to detect and fix.
When referential integrity is properly enforced, the database prevents operations that would break relationships. This creates a safety net that protects your data and ensures that your system behaves predictably.
What Happens Without Referential Integrity
If foreign key constraints are not enforced, your database becomes vulnerable to inconsistencies. For example, you could end up with orders that reference users who no longer exist, or records that point to invalid entities. These issues may not be immediately visible, but they can cause serious problems in application logic.
Over time, these inconsistencies can accumulate and make the system difficult to maintain. Debugging such issues often requires significant effort because the root cause is not always obvious. This is why referential integrity is considered a best practice in relational database design.
Handling Updates And Deletions Safely
Foreign keys allow you to define how the database should behave when related data is updated or deleted. These behaviors are controlled through constraints that determine whether changes should be restricted, cascaded, or set to null.
| Operation Type | Behavior Description | Example Outcome |
|---|---|---|
| CASCADE | Propagates changes to related records | Deleting a user deletes all orders |
| RESTRICT | Prevents deletion if related records exist | Cannot delete user with active orders |
| SET NULL | Sets foreign key to null | Order remains but user reference removed |
These options give you control over how relationships are maintained, allowing you to design systems that behave predictably under different scenarios.
Balancing Integrity And Flexibility
While referential integrity provides strong guarantees, it can also introduce constraints that limit flexibility. In some cases, strict enforcement may not align with system requirements, especially in distributed architectures where data is managed across multiple services.
This is why experienced engineers sometimes relax these constraints and handle relationships at the application level. However, this approach requires careful design to ensure that data remains consistent without relying on database enforcement.
Performance Considerations And Trade-Offs
As your system scales, performance becomes a critical factor in database design. While primary keys and foreign keys provide structure and integrity, they also introduce trade-offs that must be carefully managed. Understanding these trade-offs is essential for building systems that perform well under load.
Performance is influenced by how keys are indexed, how queries are executed, and how constraints are enforced. Each of these factors plays a role in determining the overall efficiency of your database.
Indexing And Its Impact On Performance
Primary keys are automatically indexed, which makes them highly efficient for lookups. This allows the database to retrieve records quickly, even in large datasets. Foreign keys, however, are not always indexed by default, which means you may need to create indexes manually to optimize performance.
Proper indexing can significantly improve query performance, especially when dealing with joins. However, adding too many indexes can slow down write operations because the database must update multiple structures whenever data changes. This creates a balance between read and write performance.
Join Performance And Query Complexity
Foreign keys enable join operations, which are essential for retrieving related data across tables. While joins are powerful, they can become expensive in large-scale systems, especially when multiple tables are involved. This is why query optimization becomes increasingly important as your system grows.
In some cases, engineers choose to denormalize data to reduce the need for joins. This improves read performance but introduces redundancy and potential consistency issues. Understanding when to normalize and when to denormalize is a key skill in database System Design.
Constraint Overhead In High-Scale Systems
Foreign key constraints add an additional layer of validation to database operations. While this ensures data integrity, it also introduces overhead because the database must verify relationships before executing changes. In high-scale systems, this overhead can impact performance.
This is one reason why some large-scale systems avoid enforcing foreign key constraints at the database level. Instead, they manage relationships within the application, which provides more flexibility but requires careful design to avoid inconsistencies.
Finding The Right Balance In Design
The goal of database design is to balance performance, integrity, and scalability. Primary keys and foreign keys provide essential structure, but they must be used thoughtfully to avoid unnecessary overhead. By understanding how these elements interact, you can design systems that perform efficiently without compromising data reliability.
As you continue developing your skills, you will learn to evaluate these trade-offs in the context of each system. This ability to balance competing priorities is what defines strong System Design thinking.
Primary Keys In Distributed And Scalable Systems
As systems evolve from single-node applications to distributed architectures, the role of primary keys becomes significantly more complex. At this scale, a primary key is no longer just an identifier but a critical factor that influences data distribution, system performance, and scalability. This is where many designs that work locally begin to break under real-world conditions.
In distributed systems, data is often partitioned across multiple nodes, and the primary key is typically used to determine where each record is stored. This means your choice of primary key directly impacts how evenly data is distributed and how efficiently your system handles traffic.
Auto-Increment IDs And Their Limitations
Auto-increment IDs are simple and efficient in single-node systems because they generate sequential values that are easy to index. However, in distributed environments, they introduce challenges such as coordination overhead and potential bottlenecks. Since multiple nodes cannot safely generate sequential IDs without coordination, this approach can limit scalability.
Another issue with sequential IDs is the creation of hotspots. Because new records are always added to the latest range, a single node may receive a disproportionate amount of traffic. This uneven distribution can lead to performance degradation as the system scales.
UUIDs And Globally Unique Identifiers
To address the limitations of sequential IDs, many systems use UUIDs or other globally unique identifiers. These identifiers can be generated independently across different nodes, eliminating the need for coordination. This makes them well-suited for distributed systems where scalability is a priority.
However, UUIDs come with their own trade-offs. Because they are random, they can lead to fragmented indexes and reduced performance compared to sequential IDs. This means you need to balance the benefits of scalability with the potential impact on query efficiency.
Comparing Primary Key Strategies At Scale
To better understand how different approaches perform in distributed systems, consider the following comparison.
| Primary Key Type | Advantages | Challenges |
|---|---|---|
| Auto-Increment ID | Simple, efficient indexing | Not scalable, hotspot issues |
| UUID | Globally unique, no coordination needed | Index fragmentation, larger storage |
| Composite Key | Flexible and meaningful distribution | More complex queries |
Choosing the right strategy depends on your system’s requirements. In interviews, explaining these trade-offs clearly demonstrates a strong understanding of real-world System Design.
Designing For Balanced Data Distribution
At scale, your goal is to distribute data evenly across nodes to avoid bottlenecks. This requires careful consideration of how primary keys are generated and used in partitioning. A well-designed key ensures that no single node becomes overloaded, which improves both performance and reliability.
As you design distributed systems, you will begin to see that primary key selection is not just a database decision but a system-wide concern. This broader perspective is essential for building scalable architectures.
Foreign Keys In Modern Architectures (And When They Are Avoided)
While foreign keys are fundamental to relational databases, their role changes in modern architectures, especially in distributed and microservices-based systems. In these environments, enforcing strict foreign key constraints can introduce challenges that outweigh their benefits.
As systems become more distributed, maintaining referential integrity across multiple services and databases becomes increasingly complex. This is why many large-scale systems choose to handle relationships at the application level instead of relying on database constraints.
Why Foreign Keys Are Sometimes Avoided
In distributed systems, enforcing foreign key constraints requires coordination between nodes, which can impact performance and availability. This becomes particularly challenging when data is spread across multiple services or databases. As a result, strict constraints can limit scalability.
Another reason foreign keys are avoided is the need for flexibility. In microservices architectures, each service often manages its own database, making it difficult to enforce relationships across boundaries. In such cases, relationships are maintained through application logic rather than database constraints.
Application-Level Relationship Management
When foreign keys are not enforced at the database level, the responsibility shifts to the application. This means the application must ensure that relationships remain valid and consistent. While this approach provides greater flexibility, it also increases the risk of inconsistencies if not handled carefully.
For example, a service managing orders may store a user ID without verifying its existence in another service. This requires additional validation logic and careful coordination between services. This trade-off is common in large-scale systems where performance and independence are prioritized.
Balancing Integrity And Scalability
To understand when to use or avoid foreign keys, consider the following comparison.
| Approach | Advantages | Challenges |
|---|---|---|
| Enforced Foreign Keys | Strong data integrity | Limited scalability in distributed systems |
| Application-Level Control | Greater flexibility and scalability | Risk of inconsistencies |
This comparison highlights that there is no one-size-fits-all solution. The decision depends on the system’s architecture and priorities.
Making The Right Choice In System Design
In smaller or monolithic systems, enforcing foreign keys is often the best choice because it simplifies data management and ensures consistency. In larger distributed systems, relaxing these constraints may be necessary to achieve scalability and performance.
In interviews, discussing this trade-off shows that you understand how database design evolves with system complexity. It also demonstrates your ability to adapt design principles to different architectural contexts.
Common Interview Questions On Primary And Foreign Keys
As you prepare for System Design and database interviews, questions about primary keys and foreign keys often go beyond simple definitions. Interviewers are interested in how you apply these concepts in real-world scenarios and how you reason about trade-offs.
These questions are designed to test both your foundational knowledge and your ability to think critically about database design. Being able to explain your decisions clearly is just as important as understanding the concepts themselves.
Explaining The Difference Clearly
One of the most common questions is simply asking you to explain the difference between a primary key and a foreign key. While this may seem basic, interviewers expect more than a textbook definition. They want to see that you understand how these keys function in real systems.
A strong answer connects definitions to practical use cases. For example, you might explain how primary keys ensure uniqueness within a table, while foreign keys enable relationships across tables. Adding context about performance and data integrity strengthens your response.
Designing A Schema With Relationships
Another common scenario involves designing a database schema for a given problem. In these cases, you are expected to identify entities, define primary keys, and establish relationships using foreign keys. This tests your ability to translate requirements into a structured design.
Interviewers may also ask follow-up questions about scaling or performance. This is your opportunity to discuss indexing, denormalization, and how relationships might be handled differently in large-scale systems. Demonstrating this depth of understanding sets you apart.
Discussing Trade-Offs In Real Systems
More advanced questions focus on trade-offs, such as when to avoid foreign key constraints or how primary key design affects scalability. These questions require you to think beyond theory and consider real-world constraints.
For example, you might be asked how you would design keys in a distributed system or how you would handle relationships in a microservices architecture. Providing thoughtful and balanced answers shows that you understand both the benefits and limitations of these concepts.
What Interviewers Are Really Looking For
Ultimately, interviewers are not just testing your knowledge of keys. They are evaluating your ability to reason through design decisions and communicate your thought process effectively. This is why it is important to practice explaining your ideas clearly and confidently.
A strong response typically includes a clear explanation, relevant examples, and a discussion of trade-offs. This structured approach demonstrates both technical expertise and problem-solving ability.
Practical Design Guidelines And Final Checklist
After exploring the full scope of primary keys and foreign keys, the final step is developing a practical framework for applying these concepts. This helps you approach database design with confidence, whether you are working on a real system or answering an interview question.
A structured approach ensures that you consider all relevant factors and avoid common pitfalls. It also makes your design decisions more consistent and easier to justify.
Designing With Clarity And Purpose
The first step in any database design is understanding the entities and relationships in your system. This involves identifying what data you need to store and how different pieces of data are connected. From there, you can define primary keys to uniquely identify each entity.
Once identities are established, you can use foreign keys to define relationships between entities. This ensures that your data remains structured and meaningful. By following this sequence, you create a strong foundation for your database design.
Balancing Simplicity And Flexibility
One of the key challenges in database design is balancing simplicity with flexibility. Overly complex schemas can be difficult to maintain, while overly simple designs may not capture important relationships. Finding the right balance requires careful consideration of your system’s requirements.
In some cases, it may be beneficial to relax constraints to improve performance or scalability. However, this should always be done with a clear understanding of the trade-offs involved. Maintaining this balance is a hallmark of strong database design.
A Practical Comparison For Decision Making
To summarize the key considerations, the following table provides a quick reference.
| Design Aspect | Primary Key Focus | Foreign Key Focus |
|---|---|---|
| Purpose | Unique identification | Relationship management |
| Performance Impact | Indexing and lookup efficiency | Join performance and constraints |
| Scalability Role | Data distribution and partitioning | Relationship complexity |
| Design Complexity | Key selection strategy | Relationship modeling |
This table serves as a quick guide when evaluating your design decisions. It helps you focus on the roles each type of key plays in your system.
Using structured prep resources effectively
Use Grokking the System Design Interview on Educative to learn curated patterns and practice full System Design problems step by step. It’s one of the most effective resources for building repeatable System Design intuition.
You can also choose the best System Design study material based on your experience:
Final Thoughts
Primary keys and foreign keys may seem like basic database concepts, but they form the backbone of relational database design. They define how data is structured, how relationships are maintained, and how systems perform under real-world conditions. Mastering these concepts is essential for building reliable and scalable applications.
As you continue your journey in System Design, you will find that many complex problems ultimately come down to how well your data is organized. By understanding primary key vs foreign key at a deeper level, you equip yourself with the tools needed to design systems that are both efficient and resilient.
The real value lies not in memorizing definitions, but in developing the ability to apply these concepts thoughtfully. This is what allows you to move from writing queries to designing systems that stand the test of scale and complexity.
- Updated 3 weeks ago
- Fahim
- 24 min read
