Modern APIs are designed to serve thousands or even millions of requests every day. While this accessibility is one of the reasons APIs have become the foundation of modern software, it also creates an important challenge: preventing individual clients from consuming excessive resources. API rate limiting is the mechanism that controls how frequently a client can access an API within a specified period, helping ensure that backend systems remain stable, responsive, and available for everyone.
Rather than allowing unlimited requests, a rate limiter evaluates each incoming request against a predefined policy. If the client remains within its allocated limit, the request proceeds normally. Once the limit is exceeded, additional requests are temporarily rejected until the client becomes eligible to send requests again. This simple concept plays a critical role in protecting distributed systems from overload.
Understanding the Purpose of Rate Limiting
The primary goal of rate limiting is not to prevent users from accessing an API but to ensure that every client uses shared infrastructure fairly. Without request limits, a single malfunctioning application, automated script, or malicious actor could overwhelm backend services and negatively affect every other client using the platform.
Rate limiting also allows engineering teams to predict system behavior more accurately. By placing an upper bound on incoming traffic, architects can better estimate infrastructure requirements, improve service reliability, and reduce the likelihood of cascading failures during periods of unusually high demand.
Rate Limiting Is Different from Other Traffic Controls
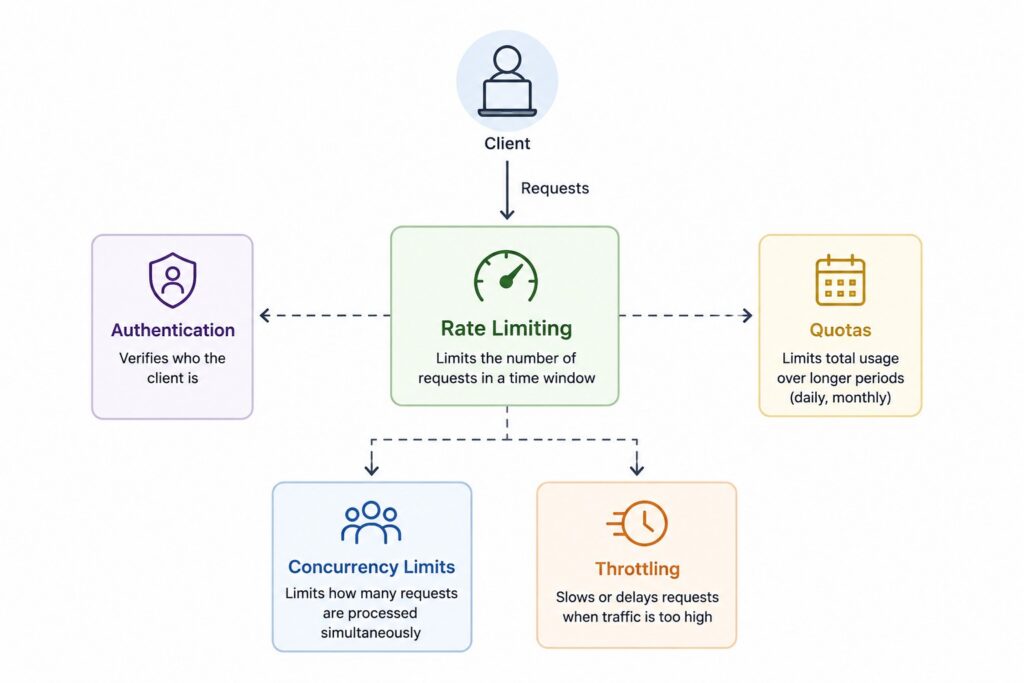
Because several traffic management techniques appear together in production systems, rate limiting is often confused with concepts such as throttling, quotas, authentication, or concurrency limits. Although these mechanisms work together, they solve different problems.
Authentication verifies who the client is before allowing access to protected resources. Quotas typically limit total usage over longer periods, such as daily or monthly API consumption. Concurrency limits control how many requests may be processed simultaneously, while throttling usually slows or delays requests when traffic becomes excessive. Rate limiting specifically controls the number of requests that may be made during a defined time window.
Understanding these distinctions is important because production APIs frequently combine multiple traffic control mechanisms rather than relying on just one.
| Concept | Primary Purpose |
|---|---|
| Rate Limiting | Control requests within a time window |
| Authentication | Verify client identity |
| Quotas | Limit long-term API usage |
| Concurrency Limits | Restrict simultaneous requests |
| Throttling | Slow or delay excessive traffic |
Why API Rate Limiting Matters
Allowing unlimited access to an API might appear harmless when an application has only a handful of users, but the situation changes dramatically as traffic grows. Public APIs, SaaS platforms, mobile applications, and AI services receive requests from thousands of independent clients with different usage patterns. Some clients generate predictable workloads, while others may accidentally or intentionally produce enormous request volumes. Without rate limiting, these requests compete equally for backend resources, making service degradation almost inevitable.
Rate limiting protects systems long before they reach their breaking point. Instead of allowing uncontrolled traffic to overwhelm infrastructure, it establishes predictable operating boundaries that improve both performance and reliability.
Protecting Backend Infrastructure
Every API request consumes resources somewhere within the system. A seemingly simple request may trigger database queries, cache lookups, authentication checks, external API calls, and message queue operations before a response is returned. When request volume grows beyond what the infrastructure can sustain, these downstream components begin to experience higher latency, resource exhaustion, and eventually service failures.
By rejecting excessive requests at the edge of the system, rate limiting prevents unnecessary work from reaching backend services. This early protection reduces load on databases, minimizes cascading failures, and allows critical infrastructure to remain available for legitimate users even during periods of unusually high traffic.
Ensuring Fair Usage
Many modern platforms serve multiple customers using the same underlying infrastructure. In these multi-tenant environments, one customer’s excessive request volume should not negatively affect everyone else. Rate limiting creates fairness by preventing a small number of clients from monopolizing shared resources.
This becomes especially important for public APIs and SaaS products where thousands of organizations may use the same platform simultaneously. Enforcing request limits ensures that every customer receives a predictable level of service regardless of how aggressively other clients use the API.
Improving Reliability and User Experience
Reliable systems depend on predictable workloads. When request volumes remain within expected limits, autoscaling behaves more effectively, latency remains stable, and engineering teams can make more accurate capacity planning decisions. Users also benefit because consistent infrastructure performance translates into faster response times and fewer unexpected outages.
Instead of reacting to overloaded systems after failures occur, rate limiting proactively keeps applications operating within healthy boundaries.
| Without Rate Limiting | With Rate Limiting |
|---|---|
| Infrastructure can become overloaded | Traffic remains within predictable limits |
| Individual clients can monopolize resources | Resources are shared fairly |
| Higher risk of cascading failures | Improved system resilience |
| Unpredictable latency | More consistent response times |
| Difficult capacity planning | More stable infrastructure utilization |
How API Rate Limiting Works
Although rate limiting appears simple from the client’s perspective, several decisions take place before an API determines whether a request should be accepted. Every incoming request must first be associated with a specific client, compared against the configured limits, and then either forwarded to the application or rejected. These operations occur within milliseconds, allowing APIs to enforce traffic policies without introducing significant latency.
Understanding this lifecycle makes it easier to appreciate why implementing rate limiting becomes increasingly complex as systems grow beyond a single server.
Identifying the Client
Before request limits can be enforced, the system must determine which client is making the request. Different applications use different identifiers depending on their security model and business requirements. Public APIs commonly identify clients using API keys, while enterprise platforms often rely on OAuth tokens, JWTs, or authenticated user accounts. In some cases, IP addresses may be used when authentication is unavailable.
Choosing the correct identifier is important because it directly affects how fairly requests are distributed. Limiting requests by IP address alone may unintentionally affect multiple users behind the same corporate network, while limiting by authenticated user provides much more precise control.
Tracking Request Counts
Once the client has been identified, the system records each request in a counter associated with that client. On a single server, maintaining these counters is relatively straightforward because all requests reach the same application instance. As soon as applications are deployed across multiple servers, however, counters must be shared so every server sees a consistent view of each client’s request history.
Many production systems use distributed in-memory stores such as Redis because they provide extremely fast counter updates while supporting multiple application instances simultaneously.
Accepting or Rejecting Requests
After updating the request counter, the rate limiter compares the current request count with the configured policy. If the client remains within its limit, the request proceeds normally through the application. If the limit has already been reached, the API rejects the request before backend resources are consumed.
Most APIs return HTTP status code 429 Too Many Requests along with headers such as Retry-After, allowing clients to understand when they can safely retry. Well-designed client applications recognize these responses and implement exponential backoff or delayed retries rather than immediately sending additional requests.
| Request Step | What Happens |
|---|---|
| Client Identification | Determine who is making the request |
| Counter Update | Record the incoming request |
| Policy Evaluation | Compare usage against configured limits |
| Request Accepted | Forward to backend service |
| Request Rejected | Return HTTP 429 with retry information |
Common Rate Limiting Algorithms
Enforcing request limits is not simply a matter of counting requests. Different applications experience different traffic patterns, and the algorithm used to measure request volume directly affects system behavior. Some algorithms are easy to implement but allow short bursts of traffic, while others provide more accurate enforcement at the cost of additional memory or computational overhead.
Selecting the right algorithm depends on balancing simplicity, performance, burst tolerance, and implementation complexity rather than searching for a universally superior solution.
Fixed Window Counter
The Fixed Window Counter is one of the simplest rate-limiting algorithms. Time is divided into fixed intervals such as one minute, and each client is allowed a predetermined number of requests during that interval. Once the window expires, the counter resets and the client may begin sending requests again.
Its simplicity makes it attractive for many applications, but it has one important limitation. A client can send the maximum number of requests immediately before one window ends and then send the same number again as soon as the next window begins, effectively doubling the allowed traffic during a very short period.
Sliding Window Log
The Sliding Window Log algorithm improves accuracy by recording the timestamp of every request instead of grouping requests into fixed intervals. Whenever a new request arrives, the system removes expired timestamps and counts only requests that occurred within the active time window.
This produces much smoother rate limiting because bursts near window boundaries are eliminated. The tradeoff is increased storage and processing overhead since every request timestamp must be maintained.
Sliding Window Counter
The Sliding Window Counter combines the advantages of fixed windows and sliding logs. Instead of storing every individual request, it maintains counters for adjacent windows and calculates an estimated request count based on how much of each window overlaps the current time.
This approach significantly reduces memory usage while providing more accurate enforcement than a simple fixed window counter, making it a common choice for production APIs.
Token Bucket
The Token Bucket algorithm generates tokens at a constant rate and stores them in a bucket until a maximum capacity is reached. Every incoming request consumes one token before being processed. If tokens remain available, requests proceed immediately. Once the bucket becomes empty, additional requests are rejected until new tokens are generated.
This algorithm is particularly effective because it allows occasional bursts of traffic while maintaining a predictable long-term request rate.
Leaky Bucket
The Leaky Bucket algorithm approaches traffic management differently by processing requests at a constant rate regardless of how quickly they arrive. Incoming requests are placed into a queue, and the system releases them steadily over time. If the queue becomes full, additional requests are discarded.
Because it smooths sudden traffic spikes, the Leaky Bucket algorithm is especially useful for protecting downstream systems that perform best under consistent workloads.
| Algorithm | Strength | Tradeoff | Common Use Case |
|---|---|---|---|
| Fixed Window | Simple implementation | Burst traffic at window boundaries | Small APIs |
| Sliding Window Log | Highly accurate | Higher memory usage | Public APIs |
| Sliding Window Counter | Balanced accuracy and efficiency | Slightly more complex | Large-scale APIs |
| Token Bucket | Supports controlled bursts | Token management required | SaaS platforms |
| Leaky Bucket | Smooth traffic flow | May delay requests | Infrastructure protection |
Choosing the Right Rate Limiting Strategy
Selecting a rate-limiting algorithm is only one part of the overall design process. Architects must also decide which clients should be limited, how different endpoints should be treated, and whether different customer tiers deserve different request budgets. These decisions influence both system reliability and the overall developer experience.
A successful rate-limiting strategy balances protection with usability. Policies that are too restrictive frustrate legitimate users, while policies that are too generous fail to protect backend infrastructure.
Limiting by User, API Key, or IP Address
The identifier used for rate limiting should reflect how clients interact with the application. API keys are commonly used for public developer platforms because they uniquely identify applications consuming the API. Authenticated user accounts work well for consumer applications where limits should apply to individual users rather than devices or networks.
IP-based rate limiting remains useful for anonymous traffic, but it has limitations because many users may share the same IP address through corporate networks or mobile carriers. For this reason, production systems often combine multiple identifiers to achieve more accurate enforcement.
Global Versus Endpoint-Specific Limits
Not every API endpoint consumes the same amount of infrastructure resources. Retrieving user profile information may require a simple cache lookup, while generating an AI response or processing a payment can involve expensive backend operations. Applying identical request limits to every endpoint often results in inefficient resource allocation.
Many platforms combine global limits with endpoint-specific policies. General requests may receive generous limits, while computationally expensive operations are protected by much stricter thresholds.
Tier-Based Rate Limits
Commercial API platforms frequently offer different request limits based on subscription plans. Free users receive lower request budgets to protect shared infrastructure, while enterprise customers benefit from significantly higher limits that reflect their contractual agreements.
Tier-based policies also provide operational flexibility. Engineering teams can adjust limits for individual customers without affecting the rest of the platform, making it easier to accommodate unique business requirements.
| Strategy | Best Used For |
|---|---|
| User-Based Limits | Consumer applications |
| API Key Limits | Public developer platforms |
| IP-Based Limits | Anonymous traffic |
| Endpoint-Specific Limits | Expensive API operations |
| Tier-Based Limits | SaaS and commercial APIs |
Implementing Rate Limiting in Distributed Systems
Implementing rate limiting on a single application server is relatively straightforward because every request reaches the same process and updates the same counters. As soon as an application scales across multiple servers, regions, or availability zones, maintaining accurate request counts becomes significantly more challenging. Multiple servers must coordinate client activity while still making rate-limiting decisions within milliseconds.
Distributed rate limiting is therefore less about counting requests and more about maintaining consistency across a highly scalable infrastructure.
Centralized Rate Limiting
One common approach is storing request counters in a centralized system such as Redis. Every API server updates the same shared counters regardless of which instance receives the request. This approach provides consistent enforcement while remaining relatively simple to implement.
The primary tradeoff is that the centralized store becomes critical infrastructure. High availability, replication, and low-latency network communication become essential because every request depends on accessing the shared counters.
Distributed Rate Limiting
Very large platforms often distribute rate limiting across multiple regions to reduce latency and eliminate single points of failure. Instead of relying on one global counter, different nodes coordinate request information while accepting that small inconsistencies may temporarily exist between regions.
This approach improves scalability and resilience but introduces additional complexity around synchronization, eventual consistency, and conflict resolution. Architects must decide whether perfect accuracy is worth the coordination overhead required to achieve it.
Where Rate Limiting Should Be Applied
Rate limiting can be implemented at several layers of the architecture, and each location offers different advantages. API gateways are a popular choice because they reject excessive requests before they reach backend services. Reverse proxies and service meshes provide similar protection closer to the network edge, while application-level rate limiting allows business-specific policies that infrastructure components may not understand.
Many production systems combine multiple layers, enforcing coarse-grained limits at the gateway while allowing applications to implement finer-grained business rules internally.
| Deployment Location | Advantages | Considerations |
|---|---|---|
| API Gateway | Centralized policy enforcement | Common choice for external APIs |
| Reverse Proxy | Early request filtering | Limited application awareness |
| Load Balancer | Basic infrastructure protection | Less flexible for API-specific rules |
| Service Mesh | Internal service protection | Best for microservices |
| Application Layer | Business-aware policies | Can duplicate logic across services |
Rate Limiting in API Gateways and Cloud Platforms
As distributed systems grow, implementing rate limiting inside every individual application quickly becomes difficult to maintain. Multiple services may expose APIs, different engineering teams may own different applications, and clients often access the platform through a single public endpoint. Modern API gateways solve this problem by centralizing rate-limiting policies before requests reach backend services, allowing organizations to enforce consistent rules across the entire platform.
This centralized approach not only simplifies implementation but also protects backend infrastructure from unnecessary traffic. By rejecting excessive requests at the edge of the system, gateways prevent overloaded services from spending valuable resources processing requests that would ultimately be rejected anyway.
Why API Gateways Are the Preferred Location
An API gateway sits between clients and backend services, making it an ideal location to enforce request limits. Since every request passes through the gateway, it can identify clients, evaluate rate-limiting policies, and reject excessive traffic before forwarding requests deeper into the architecture. Backend services remain focused on business logic instead of implementing identical traffic control mechanisms repeatedly.
Centralizing rate limiting also improves operational consistency. Engineering teams can update request limits, introduce new policies, or create customer-specific rules without modifying dozens of independent services. This separation of concerns makes large platforms significantly easier to operate as they continue to grow.
Managed Cloud Platforms
Most cloud providers include built-in rate-limiting capabilities within their API management services. Platforms such as AWS API Gateway, Azure API Management, Google Cloud API Gateway, Kong, Apigee, Envoy, and NGINX allow engineers to configure request limits using policies rather than writing custom application code. These managed solutions often integrate monitoring, authentication, analytics, and logging into the same platform, simplifying operational management.
While managed gateways reduce implementation effort, architects should still understand the underlying concepts. Choosing request limits, identifying clients, selecting algorithms, and handling distributed deployments remain architectural decisions regardless of which platform performs the enforcement.
Gateway-Based Versus Application-Level Enforcement
Although gateways provide an excellent place for enforcing most request limits, they are not always sufficient by themselves. Business-specific rules may require application-level awareness that infrastructure components do not possess. For example, an AI platform might apply different limits based on model type, token usage, or customer contracts that only the application understands.
Many production systems combine gateway-level protection with application-level policies. The gateway blocks obvious abuse and excessive traffic, while backend services enforce finer-grained business rules that depend on domain-specific knowledge.
| Deployment Approach | Advantages | Tradeoffs |
|---|---|---|
| API Gateway | Centralized policy enforcement and early request rejection | Limited business context |
| Application Layer | Business-aware request limits | Duplicated implementation across services |
| Hybrid Approach | Combines infrastructure and business policies | More operational complexity |
| Managed Cloud Gateway | Easy deployment and built-in monitoring | Platform-specific capabilities |
Rate Limiting Best Practices
Implementing rate limiting successfully involves much more than selecting an algorithm and configuring a request threshold. Well-designed policies protect infrastructure while remaining predictable and fair for developers consuming the API. Overly restrictive limits frustrate legitimate users, while overly generous limits provide little protection during traffic spikes or abusive behavior.
The most effective rate-limiting strategies evolve alongside the application. As traffic patterns change and new clients are introduced, policies should be continuously monitored, evaluated, and adjusted rather than remaining fixed indefinitely.
Choose Realistic Request Limits
Request limits should reflect how clients actually use the API rather than arbitrary numbers. Studying production traffic allows engineering teams to identify typical request volumes, seasonal spikes, and endpoint-specific workloads before establishing limits. APIs serving AI inference or payment processing often require much lower limits than lightweight read-only endpoints because every request consumes significantly more resources.
Different customer segments should also receive different request budgets when appropriate. Enterprise customers, internal services, and trusted partner integrations frequently require higher limits than anonymous public users.
Design Helpful Responses
Rejecting requests is only part of the user experience. APIs should clearly explain why a request was rejected and when clients may safely retry. Returning HTTP 429 along with headers such as Retry-After, remaining request counts, and reset times allows developers to build resilient applications that automatically recover from temporary rate limit violations.
Providing meaningful error information also reduces support requests because developers can immediately understand why their requests failed instead of assuming an application error occurred.
Monitor and Refine Policies
Rate-limiting policies should never be considered complete after deployment. Monitoring rejected requests, latency, traffic patterns, and infrastructure utilization helps identify policies that are either too restrictive or too permissive. Engineering teams can gradually adjust limits as applications grow without disrupting existing clients.
Introducing new policies incrementally is generally safer than enforcing aggressive limits immediately. A gradual rollout allows teams to observe real-world behavior before making stricter enforcement decisions.
| Best Practice | Why It Matters |
|---|---|
| Choose realistic limits | Matches actual client behavior |
| Return informative HTTP 429 responses | Improves developer experience |
| Include Retry-After headers | Enables automatic client recovery |
| Monitor rejected requests | Helps refine policies |
| Support controlled bursts | Avoids blocking legitimate traffic spikes |
| Review policies regularly | Keeps limits aligned with application growth |
Common Rate Limiting Challenges
Although rate limiting appears straightforward conceptually, implementing it reliably in production introduces several operational challenges. Distributed infrastructure, unpredictable traffic patterns, and globally deployed applications all complicate what initially seems like a simple request counter. Understanding these challenges helps architects choose appropriate algorithms and deployment strategies before systems begin operating at scale.
Many production issues occur not because rate limiting is incorrectly configured, but because the surrounding infrastructure introduces behavior that was not considered during the initial design.
Handling Burst Traffic
Not every sudden increase in requests represents malicious activity. Flash sales, software updates, marketing campaigns, and viral social media events can generate legitimate bursts that exceed normal traffic levels. A rigid rate-limiting policy may accidentally reject valid customers simply because many users became active simultaneously.
Algorithms such as Token Bucket are designed specifically to accommodate these situations by allowing temporary bursts while still enforcing sustainable long-term request rates. Choosing an algorithm that matches expected traffic patterns is often more important than selecting the strictest possible request limit.
Coordinating Distributed Counters
Maintaining accurate request counts becomes increasingly difficult as APIs expand across multiple servers and geographic regions. Every application instance must know how many requests a client has already made, even when different requests arrive at different servers. Synchronizing this information introduces additional latency, network traffic, and consistency challenges.
Some systems prioritize perfect accuracy through centralized counters, while others accept small temporary inconsistencies in exchange for higher scalability and regional independence.
Time Synchronization and High Availability
Many rate-limiting algorithms rely on timestamps, making accurate system clocks an important operational requirement. Significant clock drift between servers can produce inconsistent request evaluations, particularly for sliding window algorithms. Time synchronization services become part of the overall rate-limiting architecture.
The rate-limiting infrastructure itself must also remain highly available. If the rate limiter becomes unavailable, architects must decide whether requests should fail closed for maximum protection or fail open to preserve application availability. This tradeoff depends on the application’s security and reliability requirements.
| Operational Challenge | Common Mitigation |
|---|---|
| Burst traffic | Token Bucket or Sliding Window algorithms |
| Distributed counters | Shared data stores or coordinated synchronization |
| Clock drift | Network time synchronization |
| High availability | Replicated rate-limiting infrastructure |
| Cross-region consistency | Regional policies with eventual synchronization |
Common Misconceptions About API Rate Limiting
API rate limiting is often introduced as a straightforward protection mechanism, but several misconceptions can lead to ineffective implementations. These misunderstandings usually arise because rate limiting is closely associated with security, networking, and API management, causing engineers to assume it solves problems that actually require additional architectural components.
Clarifying these misconceptions helps build more resilient systems and prevents unrealistic expectations about what rate limiting can achieve on its own.
Rate Limiting Is Not the Same as Throttling
Although the terms are frequently used interchangeably, they describe different behaviors. Rate limiting determines whether a client has exceeded an allowed request budget during a defined time period. Throttling generally reduces request processing speed, delays requests, or gradually limits throughput instead of immediately rejecting traffic.
Many production systems use both techniques together. Rate limiting establishes hard boundaries, while throttling smooths traffic during periods of elevated demand.
Authentication Does Not Eliminate the Need for Rate Limiting
Authenticating users verifies who is accessing the API, but it does not control how aggressively they consume resources. Even trusted clients can generate excessive traffic because of software bugs, retry loops, or unexpected workloads. Authentication and rate limiting address different aspects of API protection and are most effective when used together.
Similarly, assigning every endpoint the same request limit rarely produces optimal results because different operations consume vastly different amounts of infrastructure resources.
Rate Limiting Is Only One Layer of Protection
Another common misconception is that implementing rate limiting completely protects systems from denial-of-service attacks or abusive traffic. In reality, production systems combine multiple layers, including web application firewalls, DDoS mitigation services, authentication, traffic filtering, monitoring, and autoscaling. Rate limiting contributes significantly to resilience, but it should never be viewed as the only defensive mechanism.
| Misconception | Reality |
|---|---|
| Rate limiting and throttling are identical | They control traffic in different ways |
| Authentication removes the need for limits | Authenticated users can still overload systems |
| Every endpoint needs identical limits | Different operations require different policies |
| Higher limits always improve usability | Excessive limits reduce infrastructure protection |
| Rate limiting prevents every attack | It complements broader security strategies |
API Rate Limiting in System Design Interviews
Rate limiting appears frequently in System Design interviews because it combines several important engineering concepts, including distributed systems, scalability, reliability, and API architecture. Interviewers are generally less interested in memorizing specific algorithms than in understanding when rate limiting becomes necessary, how it should be implemented, and what tradeoffs different approaches introduce.
Strong candidates explain rate limiting as part of the overall system architecture rather than treating it as an isolated feature. This demonstrates an understanding of how infrastructure components work together to protect production services.
When Should You Introduce Rate Limiting?
Rate limiting becomes necessary whenever APIs serve multiple users, expose expensive operations, or risk being overwhelmed by excessive traffic. Public APIs, authentication services, payment systems, messaging platforms, and AI inference endpoints are all common interview scenarios where introducing request limits improves both scalability and reliability.
Explaining why rate limiting belongs at a particular point in the architecture is just as important as recommending that it be implemented. Interviewers expect candidates to connect architectural decisions to concrete system requirements.
What Interviewers Evaluate
Most interviewers want to understand your reasoning rather than your ability to recall algorithm names. They may ask why you selected Token Bucket instead of Fixed Window, why counters are stored in Redis instead of application memory, or how distributed deployments maintain consistent request counts across multiple servers.
These follow-up questions reveal whether you understand the operational implications of your design rather than simply recognizing the terminology.
Common Candidate Mistakes
Candidates often recommend limiting requests solely by IP address without considering authenticated users, API keys, or multi-tenant environments. Others overlook distributed deployments entirely by assuming request counters exist only on a single server. Another common mistake is failing to explain how clients should recover after receiving HTTP 429 responses.
Addressing these considerations demonstrates practical engineering experience and strengthens the overall System Design discussion.
| Interview Topic | What Interviewers Evaluate |
|---|---|
| Algorithm Selection | Ability to justify tradeoffs |
| Counter Storage | Understanding distributed coordination |
| Deployment Location | Appropriate placement within the architecture |
| Client Identification | Fairness and accuracy of request limits |
| Failure Handling | Recovery and resilience strategies |
| Communication | Clear architectural reasoning |
Frequently Asked Questions About API Rate Limiting
API rate limiting combines concepts from networking, distributed systems, API design, and infrastructure engineering, so it naturally raises many practical questions. These questions frequently appear during production architecture discussions, platform design reviews, and System Design interviews because they focus on the real-world decisions engineers make when protecting APIs at scale.
While there is rarely a single correct answer for every application, understanding the tradeoffs behind these common questions provides a strong foundation for designing effective rate-limiting strategies.
What is the difference between rate limiting and throttling?
Rate limiting defines how many requests a client may make during a specific period of time. Once that limit is reached, additional requests are rejected until the limit resets. Throttling, on the other hand, typically slows request processing or delays responses instead of immediately rejecting traffic.
Many production platforms combine both techniques. Rate limiting establishes hard boundaries for infrastructure protection, while throttling smooths traffic and reduces sudden spikes without completely denying service.
Which rate-limiting algorithm is best?
There is no universally best algorithm because each one balances simplicity, accuracy, burst handling, and implementation complexity differently. Fixed Window is easy to implement but allows bursts near window boundaries, while Sliding Window provides greater accuracy at the cost of additional overhead.
Token Bucket has become a popular production choice because it supports short bursts while maintaining predictable long-term request rates. The appropriate algorithm depends on application requirements rather than general popularity.
Should rate limiting happen in the API gateway or the application?
For most public APIs, the API gateway is the preferred location because it rejects excessive requests before they consume backend resources. Centralizing enforcement also keeps business services focused on application logic rather than infrastructure concerns.
Application-level rate limiting still has value when business-specific policies depend on information that only the application understands. Many production systems combine gateway-level and application-level enforcement to achieve both infrastructure protection and business-aware policies.
Does rate limiting stop DDoS attacks?
Rate limiting helps reduce the impact of abusive traffic, but it does not eliminate distributed denial-of-service attacks by itself. Large-scale attacks often require additional protection such as web application firewalls, DDoS mitigation services, traffic filtering, content delivery networks, and autoscaling infrastructure.
Rate limiting should therefore be viewed as one layer within a broader defense-in-depth strategy rather than a complete security solution.
What HTTP status code should be returned when limits are exceeded?
The standard response is HTTP 429 Too Many Requests. APIs should also include headers such as Retry-After and, when appropriate, additional metadata indicating remaining request budgets or reset times.
Providing this information allows client applications to retry intelligently instead of repeatedly sending requests that will continue to be rejected.
How do large companies implement API rate limiting?
Large organizations typically enforce rate limiting through API gateways or edge infrastructure backed by distributed counter stores such as Redis. Policies are often tier-based, allowing enterprise customers, internal services, and premium subscribers to receive different request limits.
These implementations are continuously monitored and adjusted based on production traffic patterns rather than remaining static over time.
Can different users have different rate limits?
Yes. Many commercial platforms define different limits based on subscription plans, customer agreements, API endpoints, geographic regions, or application types. This flexibility allows organizations to balance infrastructure protection with customer expectations while supporting multiple service tiers.
Differentiated limits also create opportunities for premium offerings without compromising platform stability.
How should clients recover after hitting a rate limit?
Clients should avoid immediately retrying rejected requests because doing so often worsens congestion. Instead, they should respect the Retry-After header when available and implement exponential backoff to gradually retry requests after waiting an appropriate amount of time.
Well-designed client libraries automate this behavior, allowing applications to recover gracefully without requiring manual intervention from users.
| Question | Short Answer |
|---|---|
| Rate limiting vs throttling? | Rate limiting rejects requests, throttling slows them down. |
| Best algorithm? | It depends on workload characteristics. |
| Gateway or application? | Usually both, depending on the policy. |
| Does it stop DDoS attacks? | No, it complements broader security measures. |
| Which HTTP status code? | HTTP 429 Too Many Requests. |
| Can users have different limits? | Yes, based on plans or business policies. |
Final Thoughts
API rate limiting is far more than a mechanism for counting requests. It is a foundational component of modern API infrastructure that protects backend systems, ensures fair resource allocation, and improves the overall reliability of distributed applications. Whether requests originate from web browsers, mobile applications, partner integrations, or AI agents, controlling traffic intelligently helps maintain predictable system behavior even under rapidly changing workloads.
Designing an effective rate-limiting solution requires much more than selecting an algorithm. Architects must consider where limits should be enforced, how clients should be identified, how distributed counters remain consistent, and how legitimate traffic patterns differ from abusive behavior. By combining appropriate algorithms, thoughtful deployment strategies, and continuous operational monitoring, you can build APIs that remain resilient, scalable, and developer-friendly as they grow from a handful of users to millions of requests per day.
