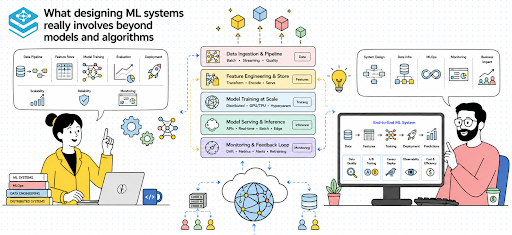
You start your journey in machine learning by building models—training classifiers, tuning hyperparameters, and optimizing metrics. At this stage, success is often measured by accuracy, precision, or recall on a validation dataset. But the moment you step into a production environment, the definition of success changes dramatically. The model is no longer the center of attention; instead, it becomes just one component in a much larger system that must operate reliably under real-world constraints.
This transition is where many engineers begin to realize that designing machine learning systems is fundamentally different from building models in isolation. The challenges shift from optimizing algorithms to managing data pipelines, deploying models at scale, and ensuring that predictions remain reliable over time. What once felt like a well-defined problem becomes a complex, interconnected system with multiple points of failure and constant evolution.
Understanding designing ML systems as a broader discipline is essential if you want to operate effectively in production environments. It requires you to think beyond code and models, and instead focus on how data, infrastructure, and operational processes come together. This article explores that reality, not as a step-by-step guide, but as a reflection of how ML systems behave and evolve in the real world.
Why ML systems are different from traditional software systems
ML systems introduce a level of uncertainty that does not exist in traditional software systems. In a typical application, the same input produces the same output, and correctness can be verified deterministically. In contrast, machine learning models produce probabilistic outputs that depend on the data they were trained on. This means that even a well-designed system can behave unpredictably when exposed to new or shifting data distributions.
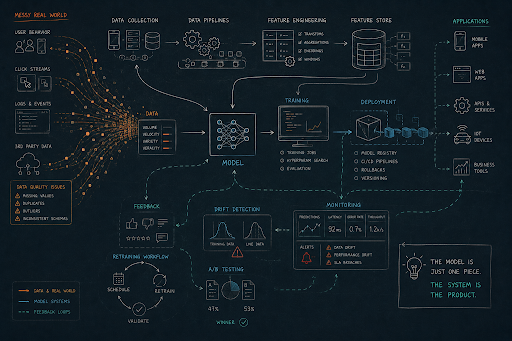
Another key difference lies in the dependency on data. Traditional systems rely on logic defined by developers, while ML systems rely on patterns learned from data. This creates a dependency chain where data quality directly affects system performance. If the data pipeline is flawed or the data distribution changes, the system’s behavior can degrade without any changes to the code itself.
Consider a fraud detection system deployed in a financial application. Initially, the model performs well, accurately identifying suspicious transactions. However, as user behavior evolves and fraud patterns change, the model begins to miss new types of fraud. The system has not failed in a traditional sense—it is still running—but its effectiveness has diminished. This kind of silent degradation is a defining characteristic of ML systems and a central challenge in their design.
Understanding designing ML systems in context
When you think about designing ML systems, it is useful to reframe the problem as designing an end-to-end pipeline rather than a single component. The model is just one part of a larger workflow that includes data collection, preprocessing, training, deployment, and monitoring. Each of these stages introduces its own challenges and trade-offs, and they must all work together seamlessly for the system to succeed.
This interconnected nature means that decisions in one part of the system can have far-reaching consequences. For example, choices made during data preprocessing can affect model performance, which in turn influences deployment strategies and monitoring requirements. Designing the system requires a holistic view, where you consider how each component interacts with the others.
The rest of this article explores these layers in more detail, focusing on how data, models, infrastructure, and operational processes come together. By understanding these interactions, you can begin to see ML systems not as isolated components, but as dynamic systems that evolve over time.
The role of data in system design
Data is the foundation of any ML system, and its role extends far beyond training a model. The way data is collected, processed, and stored has a direct impact on the system’s performance and reliability. In many cases, issues that appear to be model-related are actually rooted in data problems, such as inconsistencies, biases, or incomplete coverage.
Designing data pipelines involves making decisions about how data flows through the system. This includes handling missing values, ensuring consistency between training and inference data, and managing large-scale data processing. These pipelines must be robust, scalable, and capable of adapting to changes in data sources and requirements.
Another critical aspect is data quality. Poor-quality data can lead to misleading patterns and unreliable predictions, which can have significant consequences in production systems. Ensuring data quality requires continuous monitoring and validation, as well as mechanisms for detecting and addressing anomalies. This makes data a first-class concern in machine learning system design, rather than an afterthought.
Model lifecycle and deployment considerations
The lifecycle of a model does not end when it is trained. In fact, deployment introduces a new set of challenges that are often more complex than the training process itself. Models must be versioned, tested, and integrated into existing systems, all while maintaining reliability and performance.
One of the key challenges is managing model updates. As new data becomes available, models need to be retrained and redeployed. This process must be carefully managed to avoid introducing instability or inconsistencies. Techniques such as canary deployments and A/B testing are often used to evaluate new models before fully rolling them out.
Monitoring is another critical aspect of the model lifecycle. Once deployed, models must be continuously evaluated to ensure that they are performing as expected. This includes tracking metrics such as accuracy, latency, and resource usage, as well as detecting issues like data drift or concept drift. These considerations highlight that deployment is not a one-time event, but an ongoing process.
Infrastructure and scalability
ML systems often operate at scale, processing large volumes of data and serving predictions to millions of users. This requires infrastructure that can handle both batch processing and real-time inference. The choice between these approaches depends on the specific requirements of the application, such as latency and throughput.
Batch processing is typically used for tasks that can tolerate delays, such as generating recommendations or updating models. Real-time processing, on the other hand, is required for applications that need immediate responses, such as fraud detection or personalized search. Each approach has its own trade-offs in terms of complexity, cost, and performance.
Scalability also introduces challenges related to resource management and cost optimization. Running large-scale ML systems can be expensive, and decisions about infrastructure must balance performance with cost considerations. This requires a deep understanding of both the technical and economic aspects of system design.
Monitoring, feedback loops, and iteration
Monitoring is a critical component of ML systems, as it provides visibility into how the system is performing in production. This includes tracking not only traditional metrics like latency and throughput, but also model-specific metrics such as prediction accuracy and confidence. Effective monitoring allows you to detect issues early and take corrective action.
Feedback loops are another important aspect of ML systems. In many applications, user interactions generate new data that can be used to improve the model. Designing these feedback loops requires careful consideration of how data is collected, processed, and integrated into the system.
Iteration is an inherent part of ML systems. Unlike traditional software, which may remain stable for long periods, ML systems are constantly evolving as new data and requirements emerge. This requires a mindset that embraces change and continuous improvement, rather than static design.
Comparison of ML system components
| Component | Role in system | Key challenges | Impact on performance |
|---|---|---|---|
| Data pipelines | Collect and process data | Data quality, consistency, scalability | High (foundation of system) |
| Model layer | Generate predictions | Accuracy, generalization, drift | High (core functionality) |
| Infrastructure layer | Support training and inference | Scalability, cost, latency | High (system reliability) |
| Monitoring & feedback | Track and improve system performance | Drift detection, feedback integration | High (long-term effectiveness) |
Each of these components plays a critical role in the overall system, and their interactions determine the system’s success. Data pipelines ensure that the model has access to reliable and relevant data, while the model layer translates that data into predictions. Infrastructure supports the execution of these processes, and monitoring systems provide the feedback needed for continuous improvement.
Understanding how these components interact is essential for designing effective ML systems. Weaknesses in any one component can undermine the entire system, making it important to consider all aspects of the design. This holistic perspective is what distinguishes system-level thinking from component-level thinking.
Trade-offs in ML system design
Designing ML systems involves navigating a series of trade-offs, often between competing objectives. One common trade-off is between accuracy and latency. A more complex model may produce better predictions, but it may also require more time and resources to generate those predictions. In real-time applications, this trade-off becomes particularly important.
Another trade-off involves cost and performance. High-performance systems often require significant computational resources, which can increase operational costs. Balancing these factors requires a clear understanding of the system’s requirements and constraints.
Consider a recommendation system for an e-commerce platform. A highly accurate model might improve user engagement, but if it introduces delays in page loading, it could negatively impact the user experience. Designing the system requires finding a balance that meets both performance and usability requirements.
Common misconceptions about ML systems
One of the most common misconceptions is that the model is the system. While the model is an important component, it is only one part of a larger system. Focusing solely on the model can lead to neglecting other critical aspects, such as data pipelines and infrastructure.
Another misconception is that better models solve all problems. While improving model accuracy is important, it does not address issues related to data quality, system reliability, or scalability. These factors can have a significant impact on the overall system performance.
There is also a belief that deployment is straightforward. In reality, deploying an ML system involves a range of challenges, from integration and monitoring to scaling and maintenance. Understanding these challenges is essential for building robust systems.
How ML systems evolve in real-world environments
ML systems are not static; they evolve over time as new data and requirements emerge. This evolution requires continuous adaptation, both in terms of models and infrastructure. Systems must be designed with flexibility in mind, allowing them to accommodate changes without significant disruption.
Maintenance is a critical aspect of this evolution. As systems grow and become more complex, managing them becomes increasingly challenging. This includes updating models, maintaining data pipelines, and ensuring that the system remains reliable and efficient.
Scaling is another important consideration. As the system handles more data and users, it must be able to scale without compromising performance. This requires careful planning and ongoing optimization, making long-term thinking an essential part of ML system design.
Conclusion
Designing ML systems is about much more than building models. It involves understanding how data, infrastructure, and operational processes come together to create systems that are reliable, scalable, and adaptable. This requires a shift in perspective, from focusing on individual components to thinking in terms of systems.
By approaching ML systems with this mindset, you can better navigate the complexities and challenges of real-world environments. It is not about finding perfect solutions, but about making informed decisions and continuously improving the system over time. That is what truly defines effective ML system design.
Happy learning!
