Modern software systems rarely run on a single machine anymore, especially when applications must serve millions of users across the world. If you are preparing for backend roles or System Design interviews, understanding what is distributed systems in software engineering becomes essential for both conceptual learning and practical architecture discussions. Distributed systems form the backbone of large-scale applications such as search engines, streaming platforms, social media services, and cloud infrastructure.
At its core, distributed systems design focuses on coordinating multiple machines so they work together as a single system. These machines communicate over networks, share data, and handle requests collaboratively while maintaining performance and reliability. Learning how these systems operate helps engineers design scalable software that can grow with user demand.
Understanding What Distributed Systems Mean
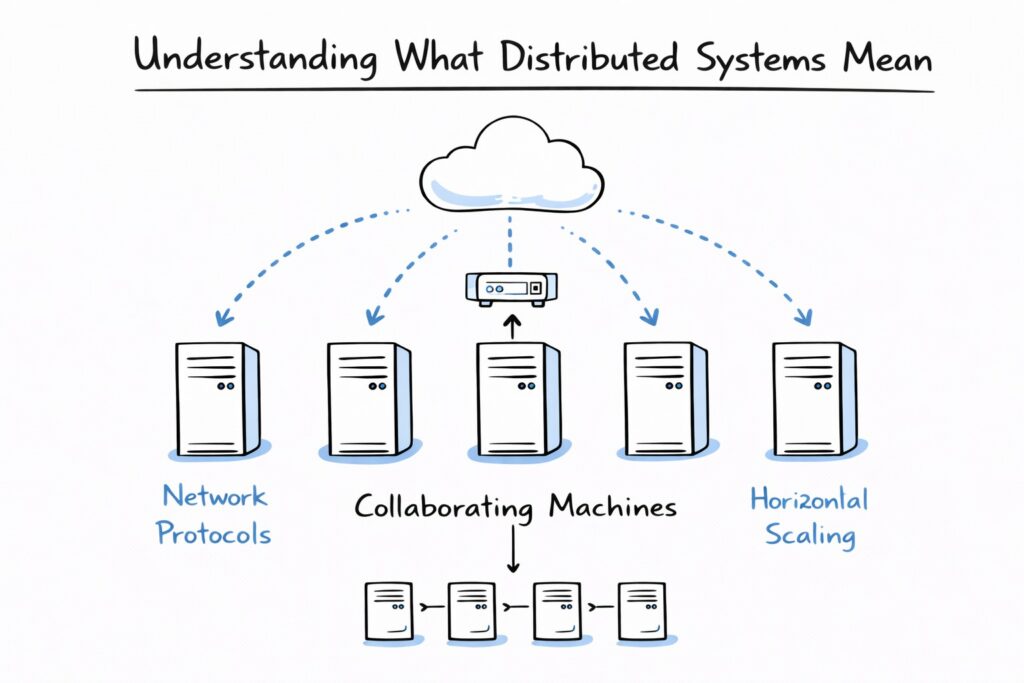
When engineers ask what is distributed systems in software engineering, they are referring to a computing architecture where multiple independent machines collaborate to provide a unified service. Each machine in the system performs part of the overall workload, and communication between them happens through network protocols. The goal is to distribute computation and storage across nodes rather than relying on a single server.
Distributed systems allow applications to scale horizontally, which means adding more machines instead of upgrading a single machine’s hardware. This architecture supports massive workloads that would otherwise overwhelm individual servers. However, distributing computation also introduces new complexities such as network failures, data consistency challenges, and synchronization issues.
These systems must ensure that users experience a seamless service even though many machines are working behind the scenes. Engineers, therefore, design coordination mechanisms, replication strategies, and monitoring systems to maintain reliability. Understanding these elements is essential for System Design interviews.
Why Distributed Systems Are Important
Understanding what is distributed systems in software engineering is important because nearly every modern large-scale application relies on distributed infrastructure. Companies such as Google, Netflix, and Amazon process enormous volumes of data and requests every second. A single server cannot handle such demand reliably.
Distributed systems enable applications to handle growth in users, traffic, and data storage requirements. They also improve fault tolerance because workloads can continue running even if individual machines fail. This resilience is critical for services that must maintain high availability.
Distributed architectures also allow services to operate across geographic regions. By deploying nodes in multiple locations, companies reduce latency for users around the world. These capabilities are why distributed systems appear frequently in System Design interview questions.
Core Characteristics Of Distributed Systems
To understand what is distributed systems in software engineering, it helps to examine the key characteristics that define these systems. Unlike centralized architectures, distributed systems must coordinate multiple nodes that operate independently while maintaining overall system coherence. Engineers must therefore design communication protocols and consistency strategies carefully.
One defining characteristic is concurrency, where many components execute tasks simultaneously. Another characteristic is the lack of a global clock, which means machines cannot perfectly synchronize time. Network reliability also becomes a major factor because communication failures can disrupt coordination.
The table below summarizes core characteristics of distributed systems.
| Characteristic | Description | Impact On System Design |
|---|---|---|
| Concurrency | Multiple nodes operate simultaneously | Requires coordination mechanisms |
| No Global Clock | Machines cannot perfectly synchronize time | Leads to ordering challenges |
| Partial Failures | Some components may fail while others continue | Requires fault tolerance mechanisms |
| Network Dependency | Nodes communicate through networks | Latency and reliability must be considered |
| Scalability | The system must grow by adding nodes | Requires partitioning strategies |
These characteristics create both opportunities and challenges when building large-scale systems.
Key Components Of Distributed Systems
Understanding what is distributed systems in software engineering also requires familiarity with the components that enable distributed operation. These components coordinate data storage, computation, and communication across machines. Each layer contributes to the overall performance and reliability of the system.
Typical distributed architectures include clients, servers, load balancers, databases, caching layers, and monitoring systems. Clients initiate requests while servers process those requests and return responses. Load balancers distribute traffic across servers to prevent overload.
Data storage components ensure that information remains accessible even when nodes fail. Replication mechanisms copy data across multiple machines for durability. Monitoring systems track performance and detect failures before they impact users.
The table below outlines common components found in distributed systems.
| Component | Role In Distributed System | Design Considerations |
|---|---|---|
| Client Application | Sends requests to system | Latency and request routing |
| Load Balancer | Distributes traffic among servers | Health checks and failover |
| Application Server | Processes user requests | Stateless vs stateful design |
| Database Cluster | Stores persistent data | Replication and consistency |
| Cache Layer | Reduces database load | Cache invalidation strategies |
| Monitoring System | Tracks system health | Logging and alerting |
Understanding how these components interact helps engineers design scalable architectures.
Communication In Distributed Systems
Communication between nodes is one of the most critical aspects of distributed systems. Since machines operate independently, they must exchange messages to coordinate tasks and share data. Network communication, therefore, becomes a fundamental part of System Design.
Distributed systems often use protocols such as HTTP, gRPC, or message queues to enable communication. Synchronous communication occurs when one service waits for another to respond. Asynchronous communication allows systems to continue processing while waiting for responses.
Choosing the right communication pattern affects latency, reliability, and throughput. In many large-scale systems, asynchronous messaging improves resilience because tasks can be retried or processed later.
Data Consistency And Replication
Another important topic when learning about distributed systems in software engineering is data consistency. When multiple machines store copies of the same data, maintaining synchronization becomes challenging. Engineers must decide how consistent the data should be across nodes.
Replication ensures that multiple machines maintain copies of data. This improves availability because requests can be served even if one node fails. However, replication introduces complexity when updates occur simultaneously.
Different systems adopt different consistency models depending on application requirements. Some prioritize strict consistency while others accept temporary inconsistencies to improve performance. These trade-offs are frequently discussed in System Design interviews.
The table below compares common consistency models.
| Consistency Model | Description | Typical Use Case |
|---|---|---|
| Strong Consistency | All nodes see the same data immediately | Financial systems |
| Eventual Consistency | Data becomes consistent over time | Social media feeds |
| Causal Consistency | Related updates appear in order | Collaborative applications |
| Read-Your-Writes | Users see their own updates immediately | User-facing applications |
Understanding these models helps engineers choose appropriate trade-offs for different systems.
Scalability In Distributed Systems
Scalability is one of the primary reasons distributed systems exist. Instead of relying on a single powerful machine, distributed architectures allow workloads to be spread across many machines. This approach enables applications to handle massive traffic growth.
Horizontal scaling involves adding more nodes to the system. Each new node increases capacity for processing requests or storing data. Load-balancing mechanisms ensure that traffic is distributed evenly across available nodes.
Partitioning techniques also improve scalability by dividing data across multiple machines. This approach prevents individual databases from becoming bottlenecks. Proper partitioning strategies ensure that systems continue operating efficiently as demand increases.
Fault Tolerance And Reliability
Distributed systems must be designed with the expectation that failures will occur. Machines may crash, networks may fail, and data centers may experience outages. Engineers build redundancy and recovery mechanisms into the architecture.
Replication ensures that data remains accessible when nodes fail. Automatic failover systems redirect traffic to healthy nodes when problems occur. Monitoring systems detect issues early so engineers can respond quickly.
Fault tolerance strategies often include retry mechanisms and graceful degradation. These techniques allow systems to maintain partial functionality even when some components fail. Reliability considerations are a major focus during System Design interviews.
Distributed Systems In System Design Interviews
Understanding what is distributed systems in software engineering is especially important for System Design interviews. Many interview questions involve designing large-scale applications that must handle millions of users. These scenarios require distributed architectures to function effectively.
Interviewers often evaluate how candidates handle topics such as load balancing, database replication, caching strategies, and failure handling. They want to see whether you understand how systems behave under heavy traffic. Explaining trade-offs between scalability, consistency, and reliability is critical.
Practicing distributed system concepts helps candidates respond confidently during these discussions. Over time, you develop intuition about common patterns such as sharding databases or using message queues. This intuition strengthens both interview performance and real-world engineering ability.
Challenges Of Distributed Systems
While distributed systems provide scalability and reliability benefits, they also introduce significant complexity. Network communication can fail unpredictably, which requires sophisticated error-handling mechanisms. Debugging issues across multiple machines can also be difficult.
Latency is another challenge because requests must travel across networks rather than within a single machine. Engineers must optimize communication paths to maintain fast response times. Monitoring tools and logging systems become essential for diagnosing performance issues.
Security considerations also increase in distributed environments. Data travels between nodes, which requires encryption and access controls. Ensuring secure communication is a critical aspect of distributed architecture design.
Conclusion
Understanding what distributed systems are in software engineering is essential for modern backend development and System Design interviews. These systems enable applications to scale across multiple machines while maintaining reliability and performance. However, they also introduce challenges related to communication, consistency, and failure handling.
By learning how distributed systems operate and why they are necessary, engineers develop the ability to design large-scale architectures with confidence. This knowledge not only improves interview performance but also prepares developers to build resilient systems capable of serving millions of users worldwide.
