Artificial intelligence products today are not powered by models alone but by complex engineering ecosystems that support training, deployment, monitoring, and scaling. This shift has created a new category of interviews focused specifically on AI systems engineering, where candidates are evaluated on their ability to design and operate production-grade AI infrastructure.
If you are preparing for such roles, you must demonstrate fluency in distributed systems, data pipelines, model lifecycle management, and performance optimization within AI contexts. Unlike traditional machine learning interviews that emphasize model theory, AI systems engineering interviews focus on building reliable, scalable, and cost-efficient AI platforms.
Interviewers want to see whether you understand how models interact with infrastructure and how engineering decisions impact performance, latency, and operational stability. In this guide, we will break down the core themes, architectural patterns, and preparation strategies that help you approach AI systems engineering interviews with clarity and confidence.
What AI Systems Engineering Really Means
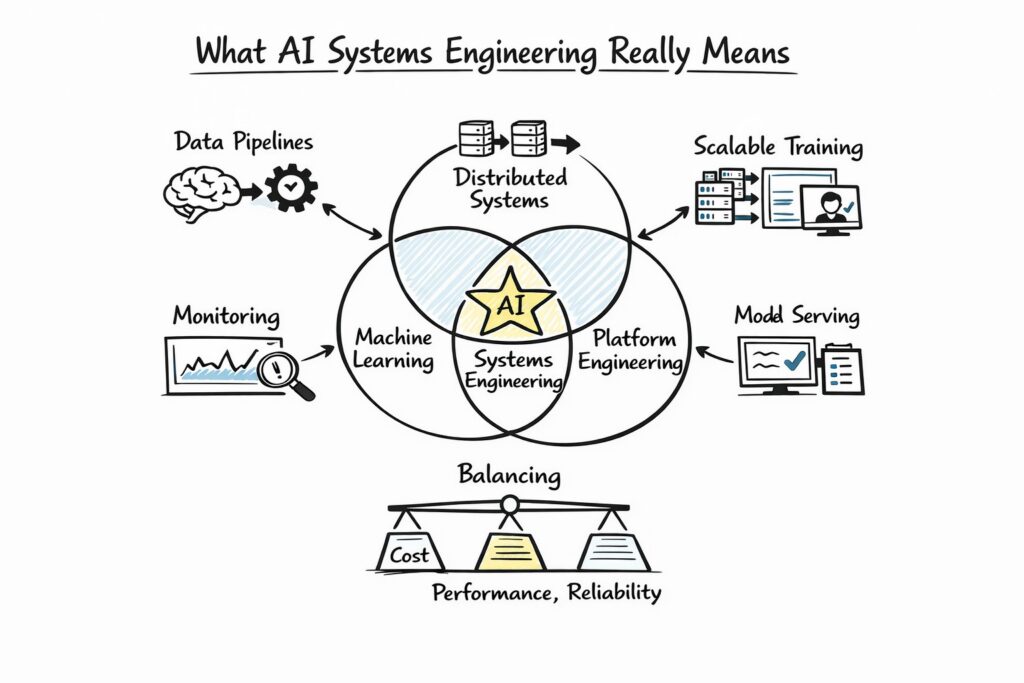
AI systems engineering sits at the intersection of machine learning, distributed systems, and platform engineering. While data scientists focus on model experimentation, AI systems engineers ensure those models can operate reliably in real-world environments with millions of users. This distinction is crucial because System Design interviews are designed to test infrastructure thinking rather than algorithmic depth alone.
An AI systems engineer is responsible for data ingestion pipelines, scalable training infrastructure, model serving frameworks, and monitoring systems that detect drift or failure. In interviews, you will often be asked to design systems that handle both offline model training and online inference while balancing cost, performance, and reliability. Understanding this dual responsibility will help you frame your answers strategically.
The following table highlights how AI systems engineering differs from adjacent roles, which interviewers often implicitly compare during evaluation.
| Role | Primary Focus | Core Responsibilities |
| Data Scientist | Model Development | Feature Engineering And Model Optimization |
| ML Engineer | Model Deployment | Training Pipelines And Model Packaging |
| AI Systems Engineer | Infrastructure And Scalability | Distributed Training, Serving, Monitoring |
| Backend Engineer | Application Logic | APIs, Databases, Business Logic |
Demonstrating awareness of this distinction signals that you understand the expectations of AI systems engineering roles beyond theoretical machine learning expertise.
Core Architectural Layers In AI Systems Engineering
To perform well in interviews, you must be comfortable discussing AI system architecture as a layered structure rather than a monolithic service. Interviewers expect structured answers that move from high-level components down to infrastructure details. A typical AI systems engineering architecture includes data ingestion, feature processing, model training, model registry management, inference services, and observability layers.
The offline training layer is often distributed across compute clusters that leverage GPU acceleration and parallelized workloads. The online inference layer prioritizes low latency and fault tolerance, frequently using container orchestration systems such as Kubernetes. Discussing the separation between these layers demonstrates architectural maturity and operational awareness.
Below is a simplified overview of these layers and their engineering focus areas.
| Layer | Engineering Focus | Key Challenges |
| Data Ingestion | Reliable And Scalable Data Collection | High Throughput And Validation |
| Feature Engineering | Consistent Feature Transformation | Training-Serving Skew |
| Model Training | Distributed Compute Optimization | GPU Scheduling And Cost |
| Model Registry | Version Control And Governance | Rollback And Traceability |
| Model Serving | Low Latency Predictions | Autoscaling And Caching |
| Monitoring | Drift And Performance Tracking | Alerting And Feedback Loops |
When answering AI systems engineering questions, walking through these layers methodically allows you to cover both infrastructure and operational trade-offs without losing structure.
Designing A Scalable Model Training Platform
One of the most common System Design interview questions involves designing a distributed training platform for large-scale models. AI systems engineering interviews frequently test your understanding of compute resource management, scheduling strategies, and data pipeline orchestration.
Start by clarifying model size, dataset scale, and expected training frequency because these variables heavily influence infrastructure decisions. For example, training small recommendation models nightly differs significantly from training large transformer models across distributed GPU clusters. Once the scope is defined, you can outline the architecture, including data storage systems, preprocessing pipelines, distributed training frameworks, and artifact storage.
Discuss resource orchestration strategies such as Kubernetes-based scheduling or managed services that allocate GPU workloads dynamically. Additionally, explain how checkpoints, failure recovery mechanisms, and distributed data parallelism improve reliability. Interviewers appreciate when candidates mention strategies to prevent wasted compute during failed training runs.
Designing A Real-Time AI Inference Platform
Another recurring scenario involves building a real-time inference platform capable of serving millions of predictions per second. AI systems engineering roles require you to balance latency, throughput, and cost under heavy traffic conditions.
Begin by clarifying acceptable latency thresholds and throughput requirements, as these determine infrastructure choices. A low-latency fraud detection system demands millisecond responses, while content recommendation engines may tolerate slightly higher latency. From there, describe how you would deploy containerized inference services behind load balancers with autoscaling capabilities.
You should also address GPU utilization optimization, batching strategies, and request caching mechanisms. In practice, many inference services batch requests internally to maximize GPU efficiency while still meeting latency constraints. Demonstrating awareness of this trade-off signals strong AI systems engineering intuition.
Handling Model Versioning And Continuous Deployment
AI systems engineering extends beyond deployment into long-term lifecycle management. Interviewers often explore how you would manage multiple model versions while ensuring minimal service disruption.
A robust deployment pipeline typically includes artifact versioning, automated validation checks, staged rollouts, and monitoring triggers. Shadow deployments allow new models to run in parallel with production models without affecting user responses, which reduces risk. Canary releases gradually increase traffic exposure, enabling safe experimentation at scale.
The following table compares common model deployment strategies in AI systems engineering contexts.
| Strategy | Deployment Pattern | Operational Risk |
| Full Replacement | Immediate Traffic Shift | Moderate |
| Canary Deployment | Gradual Traffic Increase | Low |
| Shadow Deployment | Parallel Evaluation Without Impact | Very Low |
| A/B Testing | Traffic Split Across Versions | Controlled |
Candidates who explain not only how to deploy models but also how to validate and monitor them demonstrate production-oriented thinking.
Observability And Reliability In AI Systems
Reliability in AI systems goes beyond uptime because models degrade as data distributions evolve. AI systems engineering interviews frequently test your ability to design monitoring frameworks that track both infrastructure metrics and model performance metrics.
You should describe monitoring latency, error rates, and resource utilization alongside tracking prediction accuracy, drift indicators, and feature distribution changes. Data drift detection systems compare incoming data against baseline distributions to detect anomalies. Once drift is detected, retraining pipelines may be triggered automatically or require manual review depending on system sensitivity.
Observability tools typically integrate logging, metrics dashboards, and alerting mechanisms into a unified monitoring stack. Mentioning automated retraining triggers and evaluation pipelines reflects operational maturity.
Cost Optimization In AI Systems Engineering
AI infrastructure can become prohibitively expensive without careful optimization. Interviews often include follow-up questions about controlling compute costs, particularly for GPU-heavy workloads.
You should discuss spot instance usage for training jobs, autoscaling inference clusters, and request batching strategies to improve hardware utilization. Additionally, implementing intelligent caching for repeated predictions can significantly reduce inference load. When discussing large language models, mentioning token-level cost monitoring demonstrates awareness of practical production constraints.
Balancing performance and cost is a defining responsibility of AI systems engineering roles, and articulating this trade-off strengthens your answers considerably.
Security, Governance, And Compliance Considerations
As AI systems process sensitive user data, engineering decisions must align with privacy and regulatory standards. AI systems engineering interviews increasingly incorporate questions about data governance and compliance strategies.
You should describe encryption in transit and at rest, access control policies, and audit logging frameworks. Additionally, explain how model artifacts are tracked for reproducibility and accountability. In regulated industries, compliance requirements often dictate strict monitoring and documentation practices.
Candidates who proactively mention privacy safeguards and ethical AI considerations demonstrate broader systems awareness beyond purely technical infrastructure.
Common Mistakes In AI Systems Engineering Interviews
Many candidates focus heavily on machine learning algorithms and neglect infrastructure-level trade-offs. AI systems engineering interviews prioritize architectural thinking, so diving into neural network details without discussing scalability or deployment often weakens your answer.
Another common mistake involves ignoring failure scenarios and fallback mechanisms. Production AI systems must handle model timeouts, low-confidence predictions, and degraded performance gracefully. Addressing resilience and redundancy early in your design discussion shows professional maturity.
Finally, candidates sometimes forget to clarify requirements before proposing solutions. Asking thoughtful questions about throughput, latency, model size, and retraining frequency demonstrates structured problem-solving.
How To Prepare Strategically For AI Systems Engineering Interviews
Preparation should combine distributed systems fundamentals with practical MLOps knowledge. Reviewing concepts such as container orchestration, GPU scheduling, data pipeline design, and observability frameworks will strengthen your confidence. Additionally, practicing structured answers to open-ended design prompts helps you develop clarity and composure.
When rehearsing, focus on articulating trade-offs clearly and sequentially. Begin with requirements, move to high-level architecture, dive into critical subsystems, and conclude with monitoring and optimization strategies. This repeatable framework ensures you consistently deliver comprehensive answers under time pressure.
AI systems engineering interviews reward candidates who think holistically across infrastructure, models, and operations. If you develop the habit of connecting architectural decisions to business outcomes such as cost, reliability, and user experience, you will distinguish yourself from candidates who treat AI purely as a modeling challenge.
Final Thoughts On AI Systems Engineering Interview Preparation
AI systems engineering represents the operational backbone of modern artificial intelligence applications. Companies need engineers who can design platforms that scale, adapt, and remain resilient under evolving workloads and data patterns.
Approach your preparation with a systems mindset rather than a purely algorithmic one. If you consistently demonstrate clarity in architectural thinking, awareness of infrastructure trade-offs, and understanding of long-term model lifecycle challenges, you will be well-positioned to excel in AI systems engineering interviews and contribute meaningfully to real-world AI platforms.
