Distributed systems are built on the assumption that data will be replicated across multiple machines to improve availability, fault tolerance, and scalability. While replication makes systems more resilient, it also introduces a new challenge: keeping every replica synchronized as updates occur independently across the network. Anti-entropy is the mechanism that addresses this challenge by allowing replicas to compare their state and gradually converge toward the same dataset over time.
Unlike replication protocols that focus on distributing new writes, anti-entropy focuses on repairing differences that have already occurred. It operates in the background, periodically identifying inconsistencies between replicas and synchronizing the missing updates until they eventually contain the same information.
Understanding the Goal of Anti-Entropy
The primary objective of anti-entropy is not to make every replica immediately identical after each write. Instead, it ensures that replicas that temporarily diverge because of failures, delays, or network partitions eventually become consistent again. This distinction is important because most large-scale distributed systems prioritize availability over immediate consistency.
Imagine a globally distributed database with replicas in North America, Europe, and Asia. If one region temporarily loses network connectivity, writes may continue successfully in the remaining regions while the disconnected replica falls behind. Once connectivity returns, anti-entropy compares the replicas, identifies the missing updates, and repairs the outdated node without interrupting normal application traffic.
Anti-Entropy as a Background Repair Process
One common misconception is that anti-entropy participates directly in every write request. In reality, it usually runs independently of user operations. Applications continue reading and writing data while repair processes execute in the background, gradually synchronizing replicas without requiring downtime or manual intervention.
This separation allows distributed systems to remain highly available even when temporary inconsistencies occur. Rather than blocking writes until every replica acknowledges an update, systems accept that short-lived divergence is inevitable and rely on anti-entropy to restore consistency over time.
| Concept | Description |
|---|---|
| Primary Purpose | Repair divergent replicas |
| Execution | Background synchronization process |
| Consistency Model | Supports eventual consistency |
| Trigger | Periodic repair or scheduled synchronization |
| User Impact | Usually invisible to applications |
Why Distributed Systems Need Anti-Entropy
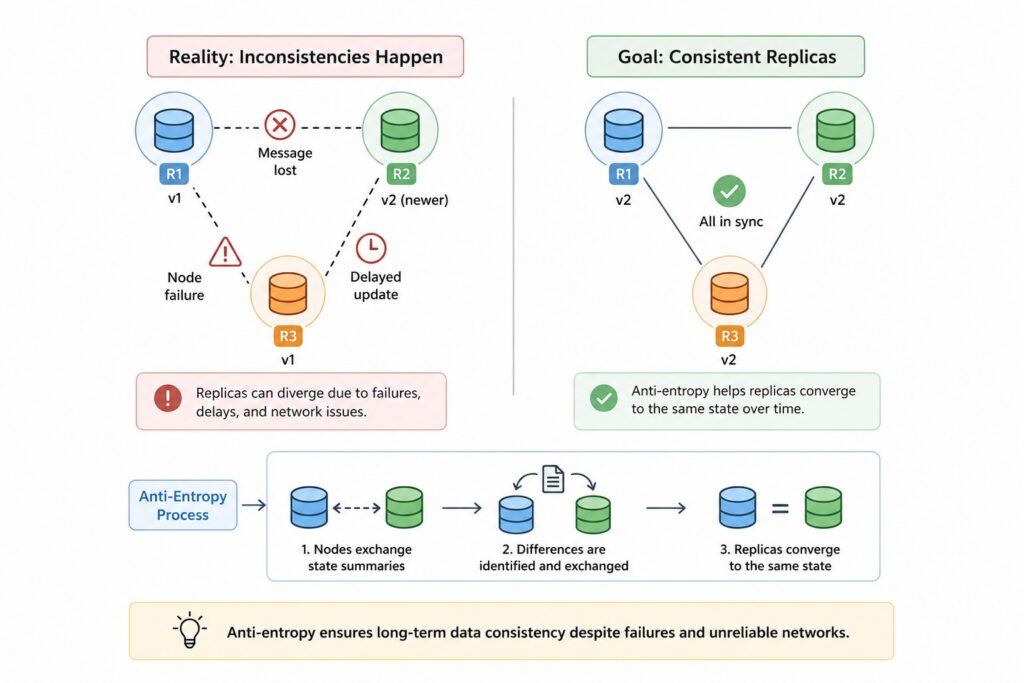
If every replica always received every update successfully, anti-entropy would never be necessary. Unfortunately, real-world distributed systems operate across unreliable networks where machines fail, messages are delayed, and entire data centers occasionally become unreachable. These realities make temporary inconsistencies unavoidable, even in carefully designed architectures.
Replication ensures that multiple copies of data exist, but it does not guarantee that every copy remains perfectly synchronized at all times. As systems grow larger and span multiple geographic regions, maintaining identical replicas becomes increasingly difficult, making anti-entropy an essential part of long-term data consistency.
Replica Divergence Happens Naturally
Replica divergence occurs whenever one or more replicas miss updates that other replicas successfully receive. This can happen for many reasons, including network partitions, overloaded nodes, temporary outages, delayed message delivery, or maintenance events. Even systems with reliable replication protocols cannot completely eliminate these situations because distributed environments are inherently unpredictable.
For example, imagine a user updating their profile while one database replica is temporarily offline for maintenance. The remaining replicas successfully process the update, but the offline replica retains the older version of the data. Once the replica returns to service, it must discover what changed during its absence and synchronize those missing updates.
Failure Is an Expected Part of Distributed Systems
Modern distributed systems are designed around the expectation that failures will occur regularly rather than exceptionally. Instead of trying to prevent every inconsistency, architects design mechanisms that detect and repair them efficiently. Anti-entropy embodies this philosophy by assuming that replicas will occasionally drift apart and providing an automated process for bringing them back into alignment.
| Failure Scenario | Resulting Inconsistency |
|---|---|
| Network partition | Replicas receive different updates |
| Node failure | Missed writes during downtime |
| Packet loss | Incomplete replication |
| Data center outage | Geographic replicas diverge |
| Delayed replication | Stale copies of data |
| Temporary overload | Replication backlog increases |
How Anti-Entropy Works
Although implementations vary between distributed databases, most anti-entropy mechanisms follow the same general workflow. Instead of copying every piece of data repeatedly, replicas periodically compare their current state, identify differences, and exchange only the updates required to eliminate inconsistencies. This incremental approach significantly reduces synchronization overhead while allowing replicas to converge efficiently.
The repair process operates independently of normal application traffic, allowing reads and writes to continue while synchronization occurs in the background. This separation enables systems to maintain high availability without forcing clients to wait for every replica to become identical.
Comparing Replica State
The first step is determining whether two replicas actually differ. Performing a complete comparison of every record would be prohibitively expensive for databases containing billions of objects, so most production systems use metadata, hashes, or hierarchical data structures to quickly identify portions of the dataset that may have changed.
Once a difference is detected, the system narrows the comparison to increasingly smaller portions of the dataset until the specific missing or outdated records are identified. Only those records are exchanged during synchronization, greatly reducing bandwidth and processing costs.
Repairing Missing Updates
After identifying inconsistent data, replicas exchange the necessary updates until both contain the same information. Depending on the database architecture, synchronization may involve copying newer records, resolving conflicting versions, or merging multiple updates using conflict-resolution strategies.
Because anti-entropy runs repeatedly over time, replicas gradually converge even if they temporarily fall behind due to failures or network interruptions. This repeated synchronization is what enables eventually consistent systems to maintain accurate replicas without requiring synchronous global coordination.
| Anti-Entropy Step | Purpose |
|---|---|
| Replica comparison | Detect differences between replicas |
| Difference detection | Locate inconsistent data |
| Data synchronization | Exchange missing updates |
| Conflict resolution | Resolve competing versions when necessary |
| Convergence | Bring replicas into alignment |
Different Types of Anti-Entropy
Not every distributed system synchronizes replicas in the same way. The direction in which updates flow during synchronization affects repair speed, network utilization, and implementation complexity. Most anti-entropy mechanisms fall into three broad categories: push, pull, and push-pull synchronization. Each approach offers different tradeoffs depending on workload characteristics and network conditions.
Selecting the appropriate synchronization strategy depends on factors such as how frequently data changes, how often replicas become disconnected, and how quickly consistency must be restored after failures.
Push Synchronization
In a push-based approach, the initiating replica sends updates that it believes another replica may be missing. This method works well when the sending node has recently processed many new writes, allowing updates to propagate quickly throughout the system. However, the sender cannot always determine whether the receiving replica already possesses the latest data, which may result in unnecessary network traffic.
Pull and Push-Pull Synchronization
Pull synchronization reverses the process by allowing a replica to request updates from another node whenever it suspects its own data is outdated. This approach reduces redundant transmissions because replicas explicitly request missing information, although repairs may occur more slowly if requests are infrequent.
Many production systems combine both approaches using push-pull synchronization. During each repair session, replicas exchange metadata, compare differences, and transfer missing updates in both directions. This hybrid strategy typically achieves faster convergence while minimizing unnecessary data transfer.
| Synchronization Method | Advantages | Limitations |
|---|---|---|
| Push | Fast update propagation | May send redundant data |
| Pull | Efficient bandwidth usage | Slower convergence |
| Push-Pull | Balanced performance and efficiency | More implementation complexity |
Merkle Trees and Efficient Replica Synchronization
One of the biggest challenges in anti-entropy is determining whether two replicas differ without comparing every individual record. For databases containing millions or even billions of objects, scanning the entire dataset during every repair cycle would consume enormous amounts of bandwidth and processing power. To solve this problem, many distributed databases use Merkle Trees, a hierarchical hashing structure that allows replicas to identify differences quickly.
Rather than comparing raw data directly, replicas compare compact cryptographic hashes that summarize increasingly smaller portions of the dataset. If two hashes match, the corresponding data is guaranteed to be identical, allowing entire sections of the database to be skipped during synchronization.
How Merkle Trees Reduce Comparison Costs
A Merkle Tree organizes data into a tree where each leaf represents the hash of a small data block, while each parent node stores the combined hash of its children. During synchronization, replicas first compare the root hash. If the root hashes match, the entire dataset is identical and no further work is required.
If the root hashes differ, replicas recursively compare lower levels of the tree until they isolate the exact branches containing inconsistent records. Only those portions require synchronization, making repair dramatically more efficient than scanning the entire database.
Why Production Databases Use Merkle Trees
Systems such as Apache Cassandra, Amazon Dynamo-inspired databases, and Riak adopted Merkle Trees because they reduce both network bandwidth and synchronization time. As datasets continue growing, these efficiency gains become increasingly important since only modified portions of the data need to be exchanged during repair operations.
| Traditional Comparison | Merkle Tree Comparison |
|---|---|
| Compare every record | Compare hierarchical hashes |
| High bandwidth usage | Minimal network traffic |
| Slow for large datasets | Efficient at massive scale |
| Entire dataset scanned | Only changed branches examined |
Anti-Entropy and Eventual Consistency
Anti-entropy is closely associated with eventual consistency, but the two concepts are not interchangeable. Eventual consistency describes the consistency model of a distributed system, while anti-entropy is one of the mechanisms used to achieve that model. Understanding this distinction is essential because many engineers mistakenly treat anti-entropy as the consistency model itself.
An eventually consistent system accepts that replicas may temporarily contain different data after updates occur. Instead of guaranteeing immediate synchronization, it guarantees that replicas will eventually converge once updates have been propagated and repair mechanisms have completed their work.
Repair Is Not the Same as Replication
Replication distributes new writes across multiple replicas as they occur, whereas anti-entropy repairs updates that replication failed to deliver successfully. Both mechanisms complement one another. Replication handles the normal flow of updates, while anti-entropy serves as the safety net that detects and repairs inconsistencies caused by failures, delays, or network partitions.
Because anti-entropy runs repeatedly, it ensures that replicas that temporarily diverged eventually converge, even when earlier replication attempts were unsuccessful.
Working Alongside Other Repair Mechanisms
Modern distributed databases rarely rely on anti-entropy alone. Systems often combine background repair with techniques such as quorum reads, quorum writes, read repair, and hinted handoff to improve consistency and reduce synchronization delays. Together, these mechanisms create resilient architectures that remain available during failures while gradually restoring consistency across all replicas.
| Mechanism | Primary Purpose |
|---|---|
| Replication | Distribute new writes |
| Anti-Entropy | Repair missed updates |
| Read Repair | Fix inconsistencies during reads |
| Hinted Handoff | Temporarily store failed writes |
| Quorum Reads/Writes | Increase consistency guarantees |
Anti-Entropy in Real Distributed Databases
Anti-entropy is not merely a theoretical concept taught in distributed systems courses. It is a core component of several production databases that prioritize high availability and horizontal scalability over immediate consistency. While each database implements anti-entropy differently, they all rely on the same underlying principle: replicas will occasionally diverge, so the system must continuously detect and repair inconsistencies without disrupting normal operations.
Rather than assuming perfect replication, these databases are designed with the expectation that failures, network partitions, and delayed updates are part of everyday operation. Anti-entropy allows them to recover gracefully from these situations while keeping applications available.
Apache Cassandra and Incremental Repair
Apache Cassandra uses anti-entropy repair to synchronize replicas that have drifted apart over time. Nodes periodically compare data ranges and exchange only the partitions that differ, reducing unnecessary network traffic. Modern versions of Cassandra also support incremental repair, allowing previously synchronized data to be skipped during future repair operations and making large clusters significantly more efficient.
Because Cassandra often powers globally distributed applications, background repair plays an important role in ensuring that replicas eventually converge after temporary failures or maintenance events.
Dynamo-Inspired Architectures
Amazon’s Dynamo introduced many of the concepts that influenced today’s eventually consistent databases. Instead of relying solely on synchronous replication, Dynamo combines replication with mechanisms such as vector clocks, hinted handoff, and anti-entropy to maintain consistency over time. Databases inspired by Dynamo, including Riak, continue to use similar repair strategies to synchronize replicas while maintaining high availability during network failures.
| Distributed Database | How Anti-Entropy Is Used |
|---|---|
| Apache Cassandra | Background and incremental replica repair |
| Amazon Dynamo | Replica synchronization after failures |
| Riak | Merkle Tree-based replica comparison |
| CouchDB | Replica synchronization between distributed nodes |
Performance Tradeoffs and Challenges
Although anti-entropy improves long-term consistency, it is not free. Every repair operation consumes network bandwidth, CPU resources, storage I/O, and memory while replicas compare datasets and exchange updates. As distributed systems continue growing, architects must carefully balance repair frequency with overall system performance to avoid creating unnecessary operational overhead.
The challenge is finding a repair strategy that maintains healthy replicas without allowing synchronization itself to become a bottleneck. This balance depends on workload characteristics, cluster size, and acceptable consistency delays.
Repair Frequency Is a Tradeoff
Running repairs continuously may reduce inconsistency windows, but it can also increase infrastructure costs and compete with application traffic for system resources. On the other hand, repairing too infrequently allows replicas to diverge further, increasing the amount of data that must eventually be synchronized and potentially exposing users to stale reads for longer periods.
Production systems schedule repair intervals based on practical operational requirements rather than attempting continuous synchronization.
Scaling Repair in Large Clusters
As clusters grow from dozens of nodes to hundreds or thousands, synchronization becomes increasingly complex. More replicas mean additional communication paths, larger datasets, and more opportunities for failures. Efficient comparison techniques such as Merkle Trees help reduce synchronization costs, but architects must still consider network utilization, repair scheduling, and fault isolation to ensure repair processes scale alongside the system itself.
| Design Decision | Benefit | Tradeoff |
|---|---|---|
| Frequent repair | Faster convergence | Higher resource consumption |
| Infrequent repair | Lower overhead | Longer inconsistency windows |
| Incremental repair | Reduced synchronization cost | Additional tracking complexity |
| Parallel repair | Faster synchronization | Increased network traffic |
Common Anti-Entropy Algorithms and Techniques
Anti-entropy is not implemented through a single algorithm. Instead, production systems combine multiple techniques to detect inconsistencies, compare replica state efficiently, and resolve conflicting updates. Each technique addresses a different part of the synchronization process, allowing distributed databases to scale while maintaining eventual consistency across large clusters.
Understanding these algorithms provides insight into why modern distributed databases can synchronize enormous datasets without repeatedly transferring every record between replicas.
Detecting and Comparing Replica State
Merkle Trees are widely used because they allow replicas to identify differences using hierarchical hashes instead of comparing complete datasets. Gossip protocols complement this process by allowing nodes to exchange metadata about cluster state and identify which replicas require synchronization. Together, these mechanisms reduce unnecessary communication while enabling efficient repair across distributed environments.
These techniques work particularly well because they exchange summaries first and actual data only when inconsistencies are discovered.
Tracking Data Versions
When multiple replicas update the same object independently, the system must determine which version should be preserved or whether conflicting versions should be merged. Techniques such as vector clocks and version vectors record causal relationships between updates, helping databases distinguish concurrent writes from sequential ones. This additional metadata allows repair processes to resolve conflicts more intelligently during synchronization.
| Technique | Primary Purpose |
|---|---|
| Merkle Trees | Efficient replica comparison |
| Gossip Protocol | Share cluster state information |
| Vector Clocks | Track update history |
| Version Vectors | Detect concurrent updates |
| Incremental Repair | Synchronize only modified data |
| Background Repair | Continuously restore consistency |
Common Misconceptions About Anti-Entropy
Because anti-entropy is often introduced alongside eventual consistency, many engineers develop an incomplete understanding of its role within distributed systems. These misconceptions can lead to incorrect architectural decisions or confusion during System Design discussions. Separating what anti-entropy actually does from what it does not do is essential for understanding modern replication systems.
Most misunderstandings arise from assuming anti-entropy replaces other replication mechanisms when, in reality, it complements them.
Anti-Entropy Does Not Guarantee Strong Consistency
One of the most common misconceptions is that anti-entropy immediately synchronizes every replica after a write. In reality, repair typically occurs asynchronously in the background, meaning different replicas may temporarily contain different versions of the same data. Strong consistency requires additional coordination mechanisms beyond background synchronization.
Similarly, anti-entropy cannot prevent conflicting updates from occurring. It simply provides a mechanism for discovering and repairing inconsistencies once they have already happened.
Repair Is Not Triggered by Every Write
Another misconception is that every write automatically initiates an anti-entropy operation. Performing full synchronization after every update would be prohibitively expensive in large distributed systems. Instead, writes are usually replicated through the normal replication protocol, while anti-entropy periodically verifies that those updates successfully reached every replica and repairs any missing data.
| Misconception | Reality |
|---|---|
| Anti-entropy guarantees strong consistency | It supports eventual consistency |
| Every write triggers repair | Repair usually runs periodically |
| Anti-entropy prevents conflicts | It repairs inconsistencies after they occur |
| Gossip and anti-entropy are identical | Gossip often supports repair but serves a different purpose |
| Replication alone eliminates divergence | Replicas can still become inconsistent |
Anti-Entropy in System Design Interviews
Anti-entropy rarely appears as a standalone interview question, but it frequently emerges during discussions about distributed databases, global replication, and eventually consistent systems. Interviewers are generally less interested in memorized definitions and more interested in whether you understand why anti-entropy exists and how it fits into larger distributed architectures.
Being able to explain the relationship between replication, consistency, and background repair demonstrates a practical understanding of how production storage systems operate.
Where the Topic Commonly Appears
You are most likely to encounter anti-entropy while designing globally distributed databases, key-value stores, or large-scale storage platforms inspired by systems such as Dynamo or Cassandra. Interviewers may ask how replicas recover after network partitions, how stale replicas are repaired, or how distributed systems maintain consistency without sacrificing availability.
These conversations often evolve into broader discussions about CAP theorem, quorum protocols, read repair, and conflict resolution.
What Interviewers Expect You to Understand
You are generally not expected to implement Merkle Trees or describe every synchronization algorithm in detail. Instead, interviewers want to know that you understand why replica divergence occurs, why background repair is necessary, and what tradeoffs anti-entropy introduces in large distributed systems. Explaining these concepts clearly demonstrates engineering intuition that extends beyond textbook definitions.
| Interview Topic | How Anti-Entropy Relates |
|---|---|
| Distributed databases | Synchronizes replicas over time |
| Eventual consistency | Enables replica convergence |
| Global replication | Repairs geographically distributed nodes |
| CAP theorem | Supports availability-first architectures |
| Dynamo-style systems | Core component of replica repair |
Frequently Asked Questions About Anti-Entropy
Anti-entropy is often discussed alongside several other distributed systems concepts, making it easy to confuse its responsibilities with those of replication, gossip protocols, or consistency models. Answering these common questions helps reinforce the role anti-entropy plays within modern distributed architectures and clarifies where it fits into the broader replication process.
Understanding these distinctions is particularly valuable because the same questions frequently arise during architecture discussions, technical interviews, and production System Design.
Is Anti-Entropy the Same as Gossip?
No. Gossip protocols primarily allow nodes to exchange metadata about cluster membership, health, or state through periodic communication. Anti-entropy focuses specifically on repairing inconsistent data between replicas. While some systems use gossip to identify which replicas require repair, the two mechanisms solve different problems.
Does Anti-Entropy Eliminate Data Conflicts?
No. Anti-entropy synchronizes replicas, but it does not inherently decide how conflicting updates should be resolved. Conflict resolution is typically handled through techniques such as vector clocks, timestamps, or application-specific merge logic before synchronized data is written back to replicas.
| Question | Answer |
|---|---|
| Is anti-entropy synchronous? | No, it usually runs asynchronously. |
| Does it guarantee consistency? | It helps achieve eventual consistency, not strong consistency. |
| Why are Merkle Trees used? | They efficiently identify replica differences. |
| Can anti-entropy prevent conflicts? | No, it repairs data after inconsistencies occur. |
| Which databases use anti-entropy? | Cassandra, Riak, Dynamo-inspired systems, and others. |
Final Thoughts
Anti-entropy is one of the foundational mechanisms that allows modern distributed systems to remain both highly available and eventually consistent. Instead of assuming replicas will always stay synchronized, it embraces the reality that failures, delayed messages, and network partitions are unavoidable in distributed environments. By continuously detecting and repairing divergence in the background, anti-entropy enables systems to recover from these failures without sacrificing scalability or availability.
Although users rarely interact with anti-entropy directly, it quietly powers many of the distributed databases that support today’s cloud applications. Whether you are designing globally distributed storage systems, preparing for System Design interviews, or studying the internals of databases such as Cassandra and Dynamo, understanding how anti-entropy works provides valuable insight into one of the most important principles of distributed systems engineering.
