When an interviewer asks you to design an API system, they are not asking you to define endpoints or write request schemas. They are evaluating whether you can design a reliable, scalable, and secure interface layer that sits between clients and backend systems. The API system is the contract boundary of the platform, and mistakes here propagate to every consumer.
In System Design interviews, this question tests your ability to think about interface stability, failure isolation, security enforcement, and operational correctness. APIs are long-lived by nature. Once clients integrate with them, changes become expensive and risky. Interviewers want to see whether you design with backward compatibility, observability, and governance in mind from the start.
APIs as a system, not just an interface
A strong answer frames the API as a system composed of multiple responsibilities. The API is responsible for validating input, authenticating callers, enforcing authorization, routing requests, shaping responses, and handling failures gracefully. It also needs to protect backend services from abuse and unpredictable client behavior.
In interviews, it is important to explicitly state that the API layer exists to decouple clients from internal service topology. Clients should not need to know how many services exist, how data is partitioned, or which services are temporarily degraded. The API system absorbs that complexity.
Public, partner, and internal APIs
The type of API heavily influences design decisions. Public APIs emphasize stability, security, strict rate limiting, and backward compatibility. Partner APIs introduce contractual SLAs and access controls. Internal APIs prioritize velocity and integration with service discovery and identity systems.
Even if the interviewer does not specify, calling out that design choices differ based on API audience shows senior-level judgment and helps frame later decisions.
Clarifying requirements and assumptions upfront
APIs often become critical infrastructure. Once clients depend on them, changing behavior can break applications, integrations, and businesses. Clarifying requirements early prevents building an API that is either too rigid to evolve or too permissive to be safe.
In interviews, this step signals that you understand APIs are contracts, not just request handlers.
Functional scope and core capabilities
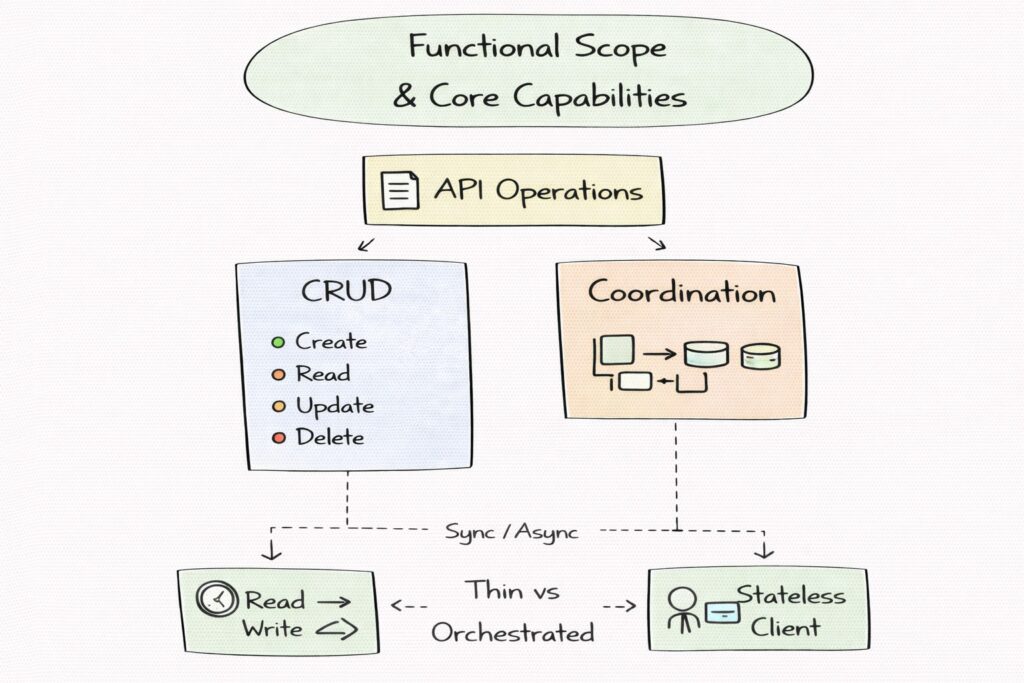
You should establish what operations the API supports and how clients interact with it. This includes understanding whether the API is primarily read-heavy or write-heavy, whether operations are synchronous or long-running, and whether the API exposes simple CRUD semantics or more complex workflows.
It is also important to clarify whether the API is stateless from the client’s perspective and how much orchestration the API layer performs. Some APIs act as thin pass-through layers, while others coordinate multiple backend services into a single response.
Client characteristics and usage patterns
API design depends heavily on who the clients are. Browser clients introduce CORS, authentication flows, and bursty traffic. Mobile clients introduce intermittent connectivity and retries. Server-to-server clients emphasize throughput, latency, and reliability.
In interviews, explicitly stating that client behavior drives retry patterns, idempotency requirements, and rate limiting shows that you design APIs for real usage, not ideal clients.
Non-functional requirements that shape the design
Latency targets influence caching, response shaping, and backend fan-out. Availability requirements influence retry strategies, fallback behavior, and multi-region deployment. Security requirements determine authentication mechanisms, authorization granularity, and audit logging.
Backward compatibility is a particularly important non-functional requirement. APIs rarely get to break clients, so versioning and deprecation strategies must be considered upfront rather than retrofitted later.
Making reasonable assumptions under ambiguity
If the interviewer leaves requirements open, it is reasonable to assume a public or partner-facing API with millions of daily requests, strict security requirements, and a need for backward compatibility. You can assume stateless API servers, horizontal scaling, and integration with multiple backend services.
Stating assumptions clearly allows you to proceed confidently while giving the interviewer space to adjust scope if needed.
High-level architecture overview
A well-designed API system is layered to separate concerns. At the outer edge, clients interact with a stable endpoint. Behind that, an API gateway or edge layer enforces cross-cutting concerns such as authentication, rate limiting, and routing. Backend services implement business logic and data access.
In interviews, starting with a layered architecture helps structure the rest of the discussion and prevents premature deep dives.
The role of the API gateway
The API gateway is the policy enforcement point of the system. It authenticates requests, validates tokens, applies rate limits, and routes requests to the appropriate backend service. It may also perform request and response transformations.
A strong interview answer emphasizes that the gateway should not contain business logic. Keeping business logic in backend services preserves flexibility and prevents the gateway from becoming a bottleneck or single point of failure.
Control plane versus data plane separation
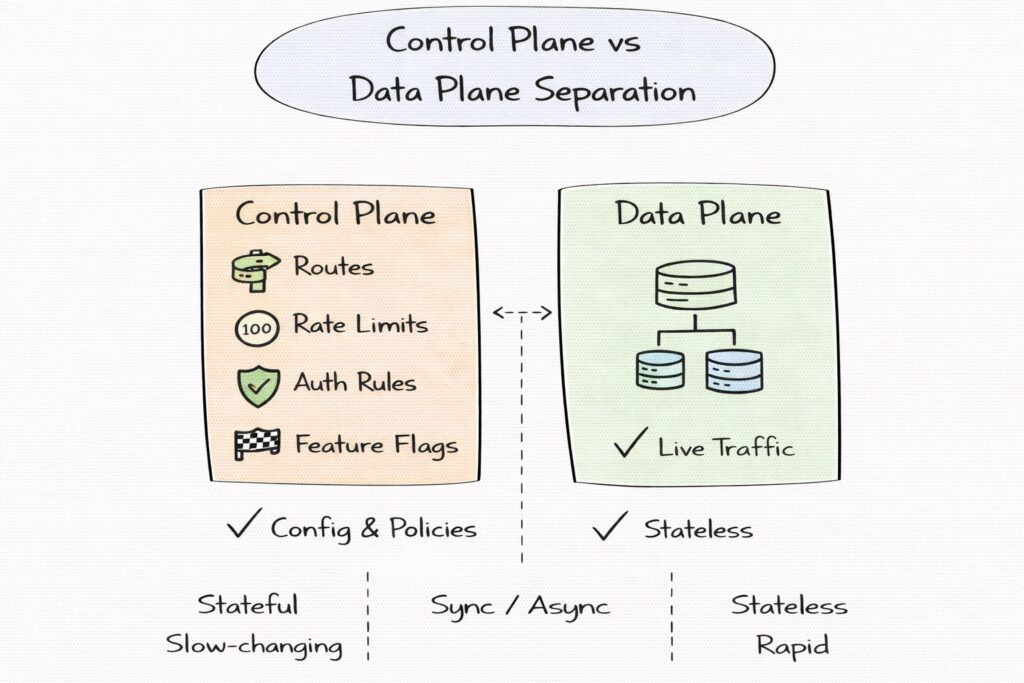
The data plane handles live traffic and must be fast, stateless, and resilient. The control plane manages configuration such as routes, rate limits, authentication rules, and feature flags. Separating these planes allows safe rollout of policy changes without disrupting traffic.
Interviewers often look for this separation because it shows operational maturity and awareness of large-scale system behavior.
Backend services and integration patterns
Behind the gateway, requests are routed to backend services. These services may be monoliths, microservices, or external systems. The API layer should shield clients from backend complexity, including service discovery, retries, and partial failures.
Explaining that the API aggregates or orchestrates responses only when necessary shows restraint and good design instincts.
API design choices: REST vs GraphQL vs gRPC
Choosing an API style is not just a developer preference. It affects performance, caching, observability, versioning, and client behavior. Interviewers expect you to understand these implications rather than reciting definitions.
A strong answer explains that different styles serve different purposes and that large systems often use more than one.
REST and resource-oriented design
REST is widely used for public APIs because it is simple, cache-friendly, and well understood. Resource-oriented endpoints map cleanly to HTTP semantics, which makes them easier to monitor, debug, and scale.
In interviews, it is valuable to note that REST works well when data models are stable and when responses can be cached or paginated effectively. Its simplicity is a strength for long-lived public APIs.
GraphQL and client-driven querying
GraphQL allows clients to specify exactly what data they need, which reduces over-fetching and under-fetching. This can improve performance for complex client applications but shifts complexity to the server.
Interviewers often probe whether candidates understand the trade-offs. GraphQL complicates caching, rate limiting, and query cost control. A strong answer explains that GraphQL systems need query validation, depth limits, and careful backend protection.
gRPC and service-to-service APIs
gRPC is commonly used for internal APIs where performance, strong typing, and schema evolution are priorities. It uses binary protocols and supports streaming, which makes it efficient for high-throughput service-to-service communication.
In interviews, it is important to clarify that gRPC is usually not ideal for public APIs due to browser limitations and debuggability, but it excels in internal systems.
Choosing the right style in practice
A mature API system often uses REST or GraphQL for external clients and gRPC for internal communication. Explaining that API style is a context-dependent decision, not a universal choice, demonstrates senior-level judgment.
Interviewers are less interested in which style you pick and more interested in whether you can justify the choice based on scalability, security, and operational needs.
Routing, load balancing, and service discovery
Routing is the mechanism that connects client intent to backend execution. In an API system, routing decisions are not static. They evolve as services are added, versions change, and deployments roll out. Interviewers care about routing because it reveals how well you isolate clients from backend churn and how safely you evolve the system.
A strong answer frames routing as a policy-driven process rather than a hardcoded mapping. The API layer should be able to route based on paths, methods, headers, versions, and even user identity, without requiring client changes.
Layer 7 routing and request steering
Most API systems use layer 7 routing, which allows decisions based on HTTP semantics. This enables path-based routing, header-based routing, and method-specific handling. For example, reads and writes can be routed to different service pools, or beta users can be routed to a canary deployment.
In interviews, explaining how routing rules are configured and rolled out safely demonstrates operational maturity. You should emphasize that routing rules live in the control plane and are applied consistently across all gateway instances.
Load balancing strategies and health awareness
Once a request is routed to a service, load balancing determines which instance handles it. Common strategies include round-robin, least-connections, and latency-aware balancing. Health checks ensure that unhealthy instances are removed from rotation quickly.
A strong answer explains that load balancing must be aware of retries and timeouts. If retries are not coordinated with load balancing, the system can amplify failures rather than recover from them.
Service discovery and dynamic environments
In modern systems, backend services scale dynamically. The API system integrates with service discovery mechanisms to maintain an up-to-date view of available instances. This may involve registries, DNS-based discovery, or platform-native mechanisms.
In interviews, it is important to emphasize that service discovery should be abstracted away from clients. The API layer absorbs backend topology changes so clients remain stable.
Avoiding retry storms and cascading failures
Retries are essential for reliability, but uncontrolled retries can overwhelm failing services. The API system should enforce timeouts, retry budgets, and circuit breakers to prevent cascading failures.
Explaining how routing and resilience mechanisms work together shows that you design APIs to fail safely under stress.
Authentication, authorization, and security controls
APIs are exposed interfaces and, therefore, natural attack surfaces. Security must be built into the API system rather than bolted on later. Interviewers expect candidates to treat authentication and authorization as core design elements, not optional features.
A strong answer distinguishes between identity verification, permission enforcement, and abuse prevention.
Authentication mechanisms and identity propagation
Authentication establishes who the caller is. Common mechanisms include API keys for simple use cases, OAuth2 and OpenID Connect for user-facing APIs, and mutual TLS for service-to-service communication. Tokens are typically validated at the gateway to reduce backend load.
In interviews, it is valuable to explain how identity information is propagated downstream in a trusted manner, often via signed headers or claims.
Authorization models and access control
Authorization determines what an authenticated caller is allowed to do. Role-based access control works well for coarse permissions, while attribute-based access control supports finer-grained policies. The API system should enforce authorization consistently across endpoints.
A strong answer explains that authorization logic should be centralized or shared to avoid policy drift across services.
Rate limiting, quotas, and abuse prevention
Rate limiting protects both the API system and backend services from abuse. Limits can be applied per API key, per user, per IP, or per endpoint. Quotas may be enforced over longer windows for billing or fairness.
Interviewers often probe how rate limiting interacts with caching and retries. Explaining that rate limits are enforced early in the request path shows good defensive design.
Threat mitigation and secure defaults
Additional security controls include request validation, payload size limits, replay protection, and secure default headers. Logging and auditing are critical for detecting and investigating security incidents.
Discussing these controls demonstrates a holistic approach to API security.
Request validation, transformation, and governance
Request validation ensures that incoming requests conform to expected schemas. This protects backend services from malformed input and reduces undefined behavior. In interviews, it is important to emphasize that validation is both a correctness and a security concern.
A strong answer explains that validation should occur as early as possible, ideally at the gateway.
Schema enforcement and contract stability
APIs are contracts. Enforcing schemas helps prevent accidental breaking changes and ensures backward compatibility. Schema definitions can also be used to generate documentation and client SDKs.
Interviewers often value candidates who connect schema enforcement to developer experience and long-term maintainability.
Request and response transformation
The API layer may transform requests and responses to normalize data formats, rename fields, or adapt between external and internal representations. This decouples client-facing contracts from backend implementations.
A strong answer emphasizes restraint. Excessive transformation can make the API layer complex and fragile.
Idempotency and safe retries
For write operations, idempotency keys allow clients to retry safely without creating duplicate side effects. The API system must store and validate idempotency tokens within a defined window.
Explaining idempotency as part of governance rather than an edge case demonstrates depth.
Policy rollout and governance at scale
In large organizations, APIs are managed by multiple teams. Governance mechanisms such as versioned policies, staged rollouts, and automated validation prevent breaking changes from reaching production.
Discussing governance shows that you think beyond a single API and consider organizational scale.
Caching, pagination, and performance optimization
Caching improves performance and reduces backend load, but it must be applied carefully in APIs due to personalization and security concerns. Cacheable responses are typically read-only and depend on stable inputs.
In interviews, it is important to distinguish between client-side caching, gateway-level caching, and CDN caching.
Conditional requests and cache validation
Techniques such as ETags and conditional headers allow clients and intermediaries to validate cached data efficiently. This reduces bandwidth and latency while preserving correctness.
Explaining these mechanisms shows that you understand HTTP semantics deeply.
Pagination, filtering, and query cost control
APIs that return large datasets must support pagination to prevent overload. Pagination strategies influence usability and performance. Cursor-based pagination often scales better than offset-based approaches for large or frequently changing datasets.
In interviews, explaining how pagination prevents expensive queries demonstrates practical performance thinking.
Payload optimization and response shaping
Reducing payload size improves latency and cost. Techniques include compression, selective field inclusion, and efficient serialization formats. The API system may allow clients to specify which fields they need, within controlled limits.
Discussing payload optimization ties performance back to user experience.
Data consistency, idempotency, and asynchronous workflows
The API system is often the first place where data consistency expectations are set for clients. Clients infer system behavior based on API responses, so ambiguity around state transitions can lead to incorrect assumptions and bugs. In interviews, explaining how the API communicates consistency guarantees shows clarity of thought.
A strong answer distinguishes between the consistency of the API contract and the consistency of underlying data stores. The API should provide clear, predictable semantics even when backend systems are eventually consistent.
Idempotency as a core reliability feature
Retries are unavoidable in distributed systems. Network timeouts, client restarts, and transient failures all cause clients to retry requests. Without idempotency, retries can create duplicate side effects such as repeated payments or duplicate records.
The API system should support idempotent writes by accepting idempotency keys and deduplicating requests within a defined window. In interviews, emphasizing that idempotency is enforced at the API layer rather than left to individual services demonstrates good boundary design.
Exactly-once behavior as an illusion
Many APIs promise “exactly once” behavior, but in practice, this is an illusion built on idempotency and careful state management. The API system should be honest about guarantees and design workflows that tolerate at-least-once execution under the hood.
Explaining this nuance shows maturity and an understanding of real-world distributed systems.
Asynchronous workflows and long-running operations
Some API operations cannot complete synchronously due to time or dependency constraints. For these cases, the API system should support asynchronous patterns such as job submission with polling, callbacks, or webhooks.
In interviews, it is valuable to explain how asynchronous APIs communicate progress, handle retries, and maintain consistent client-visible state. This demonstrates that you can design APIs beyond simple request-response interactions.
Event-driven integration patterns
APIs often integrate with event-driven systems to trigger downstream processing. The API system may publish events after successful operations or consume events to update client-visible state.
Explaining how events fit into the API system without exposing internal complexity to clients shows strong abstraction skills.
Scaling and multi-region design
API systems must scale horizontally to handle growth and traffic spikes. Stateless API servers and gateways allow new instances to be added without coordination. Shared state is externalized to data stores or caches.
In interviews, explicitly stating that the API layer is stateless signals foundational scalability understanding.
Multi-region deployment strategies
For high availability and low latency, API systems are often deployed in multiple regions. Requests may be routed to the nearest healthy region using DNS or traffic steering mechanisms. Data locality and replication strategies influence how writes and reads behave across regions.
A strong answer explains trade-offs between active-active and active-passive designs. Active-active improves availability but complicates consistency. Active-passive simplifies correctness but increases failover complexity.
Tenant and workload isolation
As usage grows, isolating tenants or workloads becomes critical. Isolation prevents noisy neighbors from degrading service for others and simplifies capacity planning.
In interviews, discussing isolation strategies shows that you design APIs for shared environments rather than single-use systems.
Throttling and adaptive load management
Under extreme load, the API system must protect itself and downstream services. Throttling, priority queues, and adaptive rate limits help ensure that critical traffic continues to flow.
Explaining how throttling integrates with client behavior and retry strategies demonstrates end-to-end thinking.
Reliability, fault tolerance, and failure handling
Failures are inevitable. The API system should degrade gracefully rather than catastrophically. This includes returning meaningful error codes, partial responses where appropriate, and fallback behavior when dependencies fail.
In interviews, describing failure modes explicitly shows preparedness and realism.
Timeouts, retries, and circuit breakers
The API system should enforce timeouts on downstream calls to avoid hanging requests. Retries should be bounded and coordinated with circuit breakers to prevent overload.
Explaining how these mechanisms interact is often more important than naming them.
Dependency isolation and bulkheads
Bulkheads isolate failures so that problems in one backend service do not cascade to others. This can be achieved through separate connection pools, thread pools, or request queues.
In interviews, highlighting isolation demonstrates awareness of real-world outage patterns.
Deployment safety and rollback
APIs evolve continuously. Safe deployment practices such as canary releases, feature flags, and fast rollback are essential to maintain reliability. The API system should support deploying new versions without breaking existing clients.
Discussing deployment safety shows that you think about the full lifecycle of the system.
Observability, analytics, and interview wrap-up with trade-offs
Observability enables teams to understand system behavior in production. Metrics, logs, and traces provide visibility into performance, errors, and usage patterns.
In interviews, it is important to explain which signals matter most and why.
Key metrics for API systems
Latency percentiles, error rates, throughput, saturation, and per-endpoint health are foundational metrics. These metrics should be collected at the gateway and service layers to enable correlation.
Explaining how metrics guide decision-making shows operational maturity.
Usage analytics and developer experience
API systems often provide analytics to API consumers, such as usage dashboards or quota visibility. These features improve developer experience and reduce support burden.
Discussing developer experience shows that you consider the API as a product.
Core trade-offs to articulate in interviews
API design involves constant trade-offs. Strict validation improves safety but reduces flexibility. Caching improves performance but risks staleness. Strong consistency simplifies reasoning but reduces availability.
Explicitly naming these trade-offs demonstrates senior-level design thinking.
How to present this design under interview constraints
In time-limited interviews, prioritize explaining boundaries, guarantees, and failure behavior. Interviewers care more about your reasoning than exhaustive detail.
Showing that you can adapt depth based on time and audience is itself a strong signal.
Using structured prep resources effectively
Use Grokking the System Design Interview on Educative to learn curated patterns and practice full System Design problems step by step. It’s one of the most effective resources for building repeatable System Design intuition.
You can also choose the best System Design study material based on your experience:
Final thoughts
Designing an API system is about much more than defining endpoints. It is about building a resilient, secure, and evolvable contract between clients and backend systems. Interviewers use API design questions to evaluate how well you think about boundaries, failure isolation, and long-term maintenance.
Strong answers emphasize clarity of guarantees, thoughtful trade-offs, and operational awareness. If you approach the problem systematically and communicate decisions clearly, API System Design becomes an opportunity to demonstrate engineering judgment rather than a checklist exercise.
