When an interviewer asks you to design a CDN System Design, they are not asking you to describe “a cache in front of a server.” They are testing whether you can reason about a globally distributed system that serves content at low latency, absorbs traffic spikes, and protects origin infrastructure from overload. A CDN is both a performance layer and a reliability layer, and interviewers use this question to evaluate your comfort with distributed systems trade-offs in the real world.
A strong interview answer treats the CDN as a product and a platform. It is a product because it directly impacts end-user experience through latency, availability, and perceived speed. It is a platform because it must support many applications and content types, often with different caching rules, security requirements, and deployment workflows.
What “content delivery” includes in modern CDNs
In interviews, it helps to quickly clarify what kinds of content your CDN serves, because the architecture differs depending on whether you’re serving images and JavaScript bundles, large video segments, software downloads, or API responses. Static assets are usually cache-friendly and benefit most from long TTLs and versioning. Video introduces huge bandwidth demands and emphasizes range requests, segmenting, and cache hierarchy. APIs and personalized responses create caching constraints and introduce edge compute and authorization.
Even if the interviewer keeps the scope broad, stating that you will optimize for static and semi-static content first gives you a clean baseline. From there, you can discuss how the same architecture evolves to handle more dynamic use cases.
What “CDN design” typically means at a systems level
A CDN design involves two major layers that you should explicitly separate early in your answer. The data plane handles the request path: edge selection, TLS termination, caching, origin fetches, and response delivery. The control plane handles orchestration and safety: configuration distribution, routing policy updates, cache invalidations, certificate management, monitoring, and fleet management.
Interviewers often look for this separation because it shows you understand how CDNs remain reliable while serving traffic at a massive scale. The data plane must be fast and resilient, and the control plane must be safe, consistent, and auditable.
Clarifying requirements and assumptions upfront
A CDN’s design is heavily shaped by constraints that aren’t always obvious at first glance. Latency targets differ by region. Content changes at different frequencies. Some content can be cached publicly, while other content must be restricted. Cost and bandwidth considerations can dictate architectural choices even when technical solutions exist.
In a System Design interview, this is the moment where you show senior judgment. You should clarify requirements, not because you lack confidence, but because the “right” CDN design depends on what is being optimized.
Functional scope to pin down early

Start by establishing what the CDN must do end-to-end. At minimum, the CDN must receive requests from users, route them to an appropriate edge location, serve cached responses when possible, fetch from the origin when needed, and enforce caching rules. Beyond that baseline, the feature scope can vary significantly.
You should clarify whether the CDN is expected to support multiple tenants or just a single application. Multi-tenancy changes everything about configuration isolation, security, and abuse prevention. You should also clarify whether the system needs to support content invalidation, signed URLs, geo restrictions, or token-based authentication. These features influence the control plane and edge request processing.
Content types and their implications
Before choosing caching strategies, you need to understand what kind of content you’re delivering. Static assets like JS/CSS bundles, images, and fonts are ideal for long-lived caching and benefit greatly from versioned URLs. Large downloads and video segments emphasize bandwidth and require a strong cache hierarchy design. Dynamic API responses may require selective caching or bypassing caches entirely.
In interviews, calling out that caching behavior depends on content type demonstrates that you’re not treating “CDN” as a single generic system.
Non-functional requirements that drive architecture
Latency and availability are the two headline requirements for a CDN, but they are not the only ones. Consistency expectations matter because CDNs serve cached data, which may be stale by design. You should clarify what freshness guarantees are needed. Some systems tolerate minutes of staleness, while others require near-instant invalidation.
Security requirements are also core. The CDN often terminates TLS, sits on the public internet, and becomes a target for abuse. You should clarify whether DDoS mitigation, WAF rules, rate limits, and strict access control are required from day one.
Cost constraints matter too. CDN design is often about optimizing cache hit ratio and minimizing expensive origin egress. If cost is a priority, you may favor more aggressive caching, mid-tier caches, or compression and optimization features.
Reasonable assumptions when details are missing
If the interviewer gives an open-ended prompt, it is reasonable to assume a global CDN serving static and semi-static assets for a web application with millions of daily users. You can assume multiple regions, edge PoPs, strict availability requirements, and a need for cache invalidation. You can also assume that long-tail regions exist where capacity is smaller and routing must fail over gracefully.
Stating these assumptions explicitly keeps your design grounded and lets the interviewer correct the scope if needed.
High-level architecture overview
A CDN architecture is easiest to explain as a globally distributed fleet of edge points of presence that sit close to users, paired with a centralized and replicated control plane that defines how traffic is handled. The edge PoPs provide low-latency serving by caching content, terminating TLS, and delivering responses quickly. The control plane distributes configuration and policy changes safely across the fleet.
This separation is critical. The edge needs to keep serving traffic even when parts of the control plane are degraded. The control plane needs strong correctness properties so that routing, security policies, and cache rules are consistently applied.
Data plane: the request-serving path
In a typical request flow, a user requests a resource and is routed to an edge PoP. The edge inspects the request, applies security and caching rules, and decides whether to serve from cache. On a cache miss, the edge fetches from an origin or from a mid-tier cache, stores the response according to policy, and returns it to the client.
The data plane must be optimized for speed and resiliency. It should handle sudden spikes without bringing down the origin. It should maintain low latency even under partial failures, and it should degrade gracefully when upstream dependencies are unhealthy.
Cache hierarchy: edge, mid-tier, and origin shielding
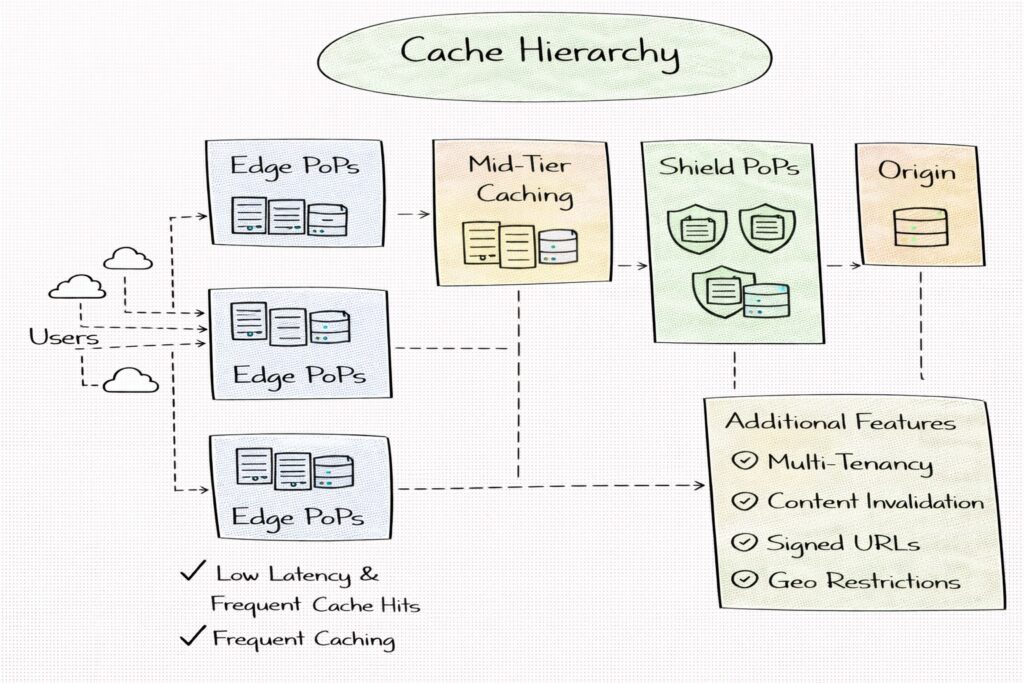
To protect origins and improve efficiency, many CDNs implement a cache hierarchy. Edge PoPs handle the last-mile latency benefit and cache the most frequently requested content. Mid-tier or regional caches reduce load on origins by serving repeated misses from the edge and providing a consolidation layer. Origin shielding routes cache misses through a small number of shield locations to prevent thundering herd effects on the origin during spikes.
Explaining this hierarchy is valuable in interviews because it demonstrates you understand that scaling CDNs is as much about origin protection as it is about end-user speed.
Control plane: policy distribution and safe operations
The control plane manages configuration and orchestration across the entire CDN. It handles routing policies, cache key configuration, TTL rules, invalidations, certificate distribution, and security policy updates. It also manages fleet health, capacity signals, and observability.
In interviews, emphasizing safe rollout mechanisms helps. Changes to routing or caching rules can cause massive outages if applied incorrectly. A mature design includes staged rollouts, validation, and rollback mechanisms.
Core data stores and configuration management
The control plane typically needs durable storage for tenant configuration, routing rules, certificates, and invalidation events. The edge needs a fast local data store for cached objects and metadata, plus mechanisms to receive configuration updates and maintain versioned policies.
Calling out that the edge should operate with locally cached configuration and only periodically synchronize with control plane systems shows that you design for resilience under control plane failures.
Request routing and edge selection
In a CDN, routing is not just “send the user to the nearest server.” It is a continuous optimization problem where you balance latency, availability, and capacity under changing network conditions. Interviewers care about routing because it determines whether your CDN is fast when things are normal and stable when things are broken.
A strong answer explains routing as a decision pipeline. First, you steer the user toward an edge region or PoP. Then the chosen edge decides how to serve the request, including whether to fetch from the origin, a mid-tier cache, or a shield. The point is that routing exists at multiple layers, and each layer uses different signals.
DNS-based routing and why it’s common
DNS-based routing is one of the most common mechanisms CDNs use to select an edge location. The idea is that the CDN’s authoritative DNS returns an IP address that corresponds to an edge PoP or a regional front door. This approach scales well and integrates naturally with how the internet routes traffic.
In interviews, it’s worth calling out the trade-offs: DNS-based routing is simple and cost-effective, but it is limited by DNS caching and TTL behavior. If you need fast failover, DNS TTLs can become a bottleneck. You can reduce TTLs, but that increases DNS query load and can create its own operational issues.
A mature design treats DNS routing as coarse-grained steering and relies on other mechanisms for fine-grained failover.
Anycast routing and what it changes
Anycast routing advertises the same IP address from multiple edge PoPs. The network then routes the client to the “closest” PoP according to BGP policies, which often correlates with low latency. Anycast can provide rapid failover because routing changes can happen at the network layer without waiting for DNS caches to expire.
The trade-off is control. Anycast gives you less deterministic steering than DNS because the routing choice is influenced by internet topology and ISP behavior. In interviews, explaining that Anycast is great for absorbing massive traffic and handling attacks, but harder to precisely steer around overloaded PoPs, signals practical understanding.
Many real CDNs blend strategies: Anycast to reach a regional ingress, then application-layer steering to pick the specific PoP or cache tier.
Application-layer steering and health-aware routing
Once the request reaches the CDN’s edge or regional ingress, you can use application-layer steering based on real-time signals. This includes PoP health, current load, cache fill level, origin health, and even per-customer policy. This layer can route around failures quickly because it is not constrained by DNS caching.
In a System Design interview, it’s valuable to describe how the system decides “best edge” beyond geography. If a nearby PoP is overloaded or partially failing, routing should shift traffic to the next-best PoP. This requires telemetry and a control plane that can push routing policies safely.
A strong design includes health signals that are both local and global. Local signals help a PoP decide whether to serve or shed load. Global signals help the control plane steer traffic away from unhealthy regions before they collapse.
Failover behavior and graceful degradation
Interviewers often ask what happens when a PoP fails, a region degrades, or the origin is down. A good routing design includes clear failover paths. If an edge PoP is unhealthy, traffic is redirected to another PoP in the same region if possible, or to a nearby region if needed. If origin health is degraded, requests may be served stale, served from mid-tier caches, or rejected with controlled error responses to avoid stampeding the origin.
Explaining failover as layered behavior rather than a single switch demonstrates that you understand CDN resilience as a system, not a routing trick.
Caching fundamentals and cache hierarchy
Caching in a CDN is not just storing files at the edge. It is a policy-driven system that decides what is cacheable, how long it stays, where it is stored, and how it is validated. In interviews, the biggest signal you can send is that you think about caching as a combination of correctness and performance.
The cache must also work across many tenants and content types. A caching strategy that is perfect for static images can be harmful for personalized content. Strong answers show you can create a cache system that adapts to the content rather than forcing all traffic into the same pattern.
Cache keys and avoiding fragmentation
The cache key is the identity of a cached object. If your cache key is too broad, you risk serving the wrong content. If it is too specific, you fragment the cache and destroy the hit ratio. The key design question is what parts of the request should be included. URL path is obvious, but query parameters, headers, cookies, and device variants can increase the number of unique keys.
In interviews, it helps to explain that a CDN typically normalizes requests before caching. It may drop tracking parameters, standardize header casing, or define explicit “vary” rules so that only the important variants create separate cache entries. This is a major real-world issue because fragmentation can silently reduce performance and increase cost.
TTLs, cache-control, and policy enforcement
CDNs typically respect cache-control directives from origins, but mature designs also allow override policies. For example, the CDN might enforce a minimum TTL to protect origins from repeated misses, or enforce a maximum TTL to ensure freshness for frequently changing assets.
A strong interview explanation distinguishes between client caching and CDN caching. Even if the client must not cache content, the CDN might cache it privately to protect the origin. That distinction is a practical performance tool and a subtle point interviewers like to see.
Multi-layer caching: edge, mid-tier, and origin shield
A cache hierarchy helps reduce origin load and improves cache efficiency. Edge caches provide low latency but have limited storage and high churn. Mid-tier caches consolidate demand across multiple edges and store content longer, which increases hit ratios for less frequently accessed content. Origin shields act as controlled chokepoints that prevent thundering herd behavior by ensuring that many edge misses become a single upstream request.
In interviews, the most important reason is why hierarchy exists. It is not only to increase hit ratio, but to protect origins from bursty traffic patterns, cache evictions, and synchronized expirations.
Handling cache misses and request coalescing
When many clients request the same object at the same time, and it is not cached, the CDN can accidentally overload the origin with duplicate fetches. Mature CDNs use request coalescing so only one upstream fetch is in flight for a given cache key while other requests wait.
Explaining coalescing and thundering herd prevention is a strong signal. It shows you’ve thought about the worst-case behaviors CDNs face during launches, cache purges, or viral events.
Cache invalidation, freshness, and consistency
Caching is easy until content changes. Invalidation is hard because you have many distributed caches, each with its own local state, and you must reconcile correctness with scalability. Interviewers love this section because it forces you to reason about distributed consistency, staleness tolerance, and operational safety.
A strong answer begins by clarifying freshness requirements. If the business can tolerate a small window of staleness, you can design a simpler, safer system. If the business requires near-instant global updates, your control plane must support low-latency propagation and careful failure handling.
Versioned assets as the simplest freshness strategy
For static assets, versioned URLs are the cleanest approach. When content changes, you publish it at a new URL, and caches treat it as a new object. This avoids global invalidation storms and makes caching extremely efficient. In interviews, emphasizing that good System Design often avoids invalidation rather than building complex invalidation mechanisms is a strong judgment signal.
You can still have invalidation for emergencies, but versioning becomes the default approach for predictable performance.
Explicit invalidation and purge propagation
When versioning is not enough, you need explicit invalidation. This typically means the control plane creates an invalidation event that is propagated to relevant PoPs. The edge then marks cache entries as invalid or removes them.
The design challenge is propagation at scale. If you push invalidations to every PoP synchronously, you risk control plane overload and delayed propagation. A more robust design treats invalidations as events that propagate asynchronously, with acknowledgement tracking and retries. The edge should apply invalidations idempotently, so duplicates do not cause issues.
Interviewers often probe what happens if invalidation messages are delayed or lost. A good design includes replayability, durable invalidation logs, and a way for PoPs to catch up after downtime.
Soft TTLs, revalidation, and serving stale
A common strategy in CDNs is separating “freshness” from “servability.” Soft TTLs determine when an object should be revalidated, while hard TTLs determine when it must not be served. This allows the edge to serve slightly stale content during transient origin failures, preserving availability and user experience.
In interviews, it’s powerful to explain how the CDN balances correctness with reliability. Serving stale content is often acceptable for static assets but may be unacceptable for pricing or security-sensitive data. The key is policy-driven behavior, not a single global rule.
Avoiding inconsistent versions during rollouts
One subtle problem is mixed versions of content during deployments. If some PoPs have received invalidations or updated content and others have not, users in different regions may see different versions. That may be acceptable for some systems but unacceptable for others.
A strong answer explains strategies to reduce visible inconsistency. Versioned URLs reduce the problem for static content. For HTML or APIs, you may need staged rollout policies, cache-bypass windows, or origin-controlled cache-control directives during releases.
Preventing invalidation storms and origin overload
Large invalidations can cause sudden cache miss spikes, which shift load to origins and can cause outages. A robust CDN design includes rate limiting for invalidations, gradual purge strategies, and origin shielding to absorb the miss storm. It may also include proactive prewarming for critical content.
In interviews, tying invalidation behavior back to origin protection demonstrates that you understand the full system impact, not just cache correctness.
Content ingestion and origin integration
The origin is the authoritative source of truth for content served by the CDN. A well-designed CDN minimizes direct origin traffic, but it must integrate cleanly with origin systems to ensure correctness and reliability. In interviews, it is important to frame the origin as a dependency that must be protected rather than a component that can scale infinitely.
The CDN should treat the origin as a scarce resource. Every design decision around caching, routing, and invalidation ultimately exists to reduce load and volatility at the origin layer.
Pull-based versus push-based ingestion models
Most CDNs operate in a pull-based model. When an edge cache misses, it fetches the object from the origin and stores it according to policy. This model scales naturally because content is only fetched when needed and because it avoids pushing large datasets to every edge upfront.
Push-based ingestion is sometimes used for critical or highly predictable content. In this model, content is proactively uploaded to the CDN, often to mid-tier caches or specific PoPs. In interviews, it is valuable to explain that push models offer lower cold-start latency but introduce complexity in deployment pipelines and storage management.
A mature CDN design supports both models and allows operators to choose based on content characteristics.
Origin shielding and request consolidation
Origin shielding is a key technique for protecting origins from bursty traffic. Instead of allowing every edge to fetch directly from the origin, edges route cache misses through a small number of designated shield locations. This consolidates requests and dramatically reduces duplicate origin fetches.
In interviews, explaining origin shielding as a way to smooth traffic spikes and reduce thundering herd effects shows deep operational understanding. It also ties back to earlier discussions about cache hierarchy and miss amplification.
Authentication, authorization, and trust boundaries
The CDN must authenticate itself to the origin to prevent unauthorized access and abuse. This may involve mutual TLS, signed requests, or token-based authentication. The origin should trust the CDN but still enforce access control based on headers or credentials provided by the CDN.
Explaining trust boundaries is important. The CDN often sits in front of private origins that are not publicly accessible. A strong design ensures that only the CDN can reach the origin and that origin exposure is minimized.
Multi-origin support and failover
Many applications use multiple origins, either for redundancy or because content is stored in different backends. The CDN must support routing to different origins based on request attributes or health signals.
In interviews, discussing origin failover behavior is valuable. If the primary origin becomes unavailable, the CDN may retry against a secondary origin, serve stale content, or degrade functionality. Clear failover rules prevent cascading failures and protect user experience.
Handling dynamic content, personalization, and edge compute
CDNs were originally built for static content, but modern applications rely heavily on dynamic and personalized responses. Dynamic content reduces cacheability and increases origin dependency, which undermines many of the benefits of a CDN.
In interviews, acknowledging this tension up front shows realism. The goal of CDN design in this context is not to cache everything, but to intelligently decide what can be cached, where logic should run, and how to minimize unnecessary origin traffic.
Selective caching and cache bypass rules
Dynamic content often includes user-specific data or authorization checks. The CDN must decide when to bypass the cache entirely and forward requests directly to the origin. This decision is usually policy-driven and based on request headers, cookies, or authentication tokens.
A strong answer explains that even when responses are not cached, the CDN still adds value by terminating TLS, applying security rules, and absorbing traffic spikes.
Edge compute and request normalization
Modern CDNs often support lightweight computation at the edge. Edge compute can be used to normalize requests, rewrite headers, perform redirects, or apply simple logic before routing to cache or origin. This helps reduce cache fragmentation and simplifies origin logic.
In interviews, it is important to emphasize that edge compute should remain stateless and constrained. Stateful logic at the edge introduces complexity, consistency issues, and operational risk.
Authentication and authorization at the edge
For protected content, the CDN may validate tokens or signatures at the edge before deciding whether to serve cached content or forward to the origin. This reduces load on the origin and improves latency.
Explaining how the edge enforces access control while maintaining cache efficiency demonstrates a nuanced understanding of security-performance trade-offs.
A/B testing and experimentation at the edge
Some CDNs support traffic splitting for experiments or gradual rollouts. Edge logic can assign users to variants and route requests accordingly. This allows experimentation without modifying the original code.
In interviews, highlighting this capability shows awareness of how CDNs integrate into modern deployment and experimentation workflows.
DDoS protection, rate limiting, and security controls
A CDN sits on the public internet and often becomes the first point of contact for user traffic. This makes it a natural target for attacks. In practice, CDNs are as much a security infrastructure as they are a performance infrastructure.
In interviews, treating security as a core responsibility rather than an add-on signals senior-level thinking.
Absorbing and mitigating DDoS attacks
CDNs are uniquely positioned to absorb volumetric attacks because they operate large, globally distributed networks. By spreading traffic across many PoPs and using Anycast, CDNs can prevent any single location from being overwhelmed.
A strong answer explains that DDoS mitigation includes both capacity and intelligence. Capacity absorbs floods, while detection systems identify abnormal patterns and trigger mitigation rules.
Rate limiting and abuse prevention
Rate limiting protects both the CDN and the origin from abusive clients. Limits can be applied per IP, per token, per region, or per endpoint. Effective rate limiting requires accurate client identification and fast enforcement at the edge.
In interviews, explaining how rate limiting integrates with routing and caching policies shows that you see the system holistically.
Web application firewall and request inspection
Many CDNs include WAF functionality to inspect requests for malicious patterns. This includes SQL injection attempts, XSS payloads, and protocol violations. These checks must be fast and configurable to avoid adding latency or false positives.
Discussing WAF rules as part of the CDN control plane reinforces the idea that security policies must be distributed and updated safely.
TLS termination and certificate management at scale
CDNs commonly terminate TLS at the edge. This improves performance and allows the CDN to inspect traffic for security and caching decisions. However, it introduces the challenge of managing certificates across thousands of PoPs.
In interviews, mentioning automated certificate provisioning, rotation, and revocation demonstrates operational maturity.
Tenant isolation and blast radius control
In multi-tenant CDNs, one customer’s traffic or misconfiguration must not impact others. Isolation at the configuration, routing, and capacity levels helps prevent cascading issues.
Highlighting isolation strategies shows awareness of real-world CDN failures and how they are prevented.
Scalability, capacity planning, and cost optimization
Scaling a CDN is fundamentally different from scaling a typical backend service. The challenge is not just handling more requests, but doing so while maintaining low latency, high cache efficiency, and predictable cost. Traffic is bursty, geographically skewed, and often driven by external events such as launches or viral content.
In interviews, it helps to explain that CDN scalability is about absorbing spikes gracefully rather than just increasing average throughput.
PoP capacity planning and geographic distribution
Each point of presence has finite compute, storage, and network capacity. Capacity planning involves deciding how many PoPs to deploy, where to place them, and how much headroom to reserve for traffic spikes. Some regions require large capacity due to high traffic volume, while others serve as smaller fallback locations.
A strong answer explains that overprovisioning everywhere is cost-prohibitive. Instead, CDNs rely on intelligent routing, regional failover, and cache hierarchy to handle uneven demand.
Load shedding and graceful degradation
When a PoP approaches capacity limits, the CDN must shed load in a controlled manner. This may involve redirecting traffic to neighboring PoPs, serving lower-fidelity content, or prioritizing critical traffic. The goal is to protect the system as a whole rather than maximizing service at a single location.
In interviews, discussing graceful degradation shows that you design for survival under stress, not just ideal performance.
Optimizing cache efficiency to reduce cost
Cache hit ratio is one of the most important levers for both performance and cost. Higher hit ratios reduce origin egress, network usage, and compute load. Techniques such as request normalization, longer TTLs for safe content, and multi-tier caching all contribute to better efficiency.
Explaining how design choices improve cache hit ratio demonstrates that you understand the economic realities of CDN operation.
Bandwidth and compute cost controls
CDNs incur significant bandwidth costs, especially for large assets like video. Compression, image optimization, adaptive bitrate streaming, and protocol optimizations help reduce egress volume. Compute cost can be controlled by limiting expensive edge logic and prioritizing fast, simple request paths.
In interviews, tying technical design to cost outcomes is a strong differentiator.
Reliability, fault tolerance, and disaster recovery
Failures are inevitable in globally distributed systems. PoPs go offline, network links degrade, and origins fail. A CDN must be designed to continue serving traffic under these conditions with minimal user impact.
Interviewers often look for candidates who assume failure is normal rather than exceptional.
PoP-level and regional failover
When a PoP becomes unhealthy, traffic should be automatically rerouted to another nearby PoP. If an entire region fails, traffic must shift to other regions, even at the cost of higher latency. Routing systems must detect failures quickly and avoid oscillation or routing loops.
A strong answer explains how routing, health checks, and load signals work together to enable fast failover.
Origin failure handling and stale serving
If the origin becomes unavailable, the CDN may continue serving cached content beyond its normal TTL. This trades freshness for availability and is often acceptable for static or semi-static content. For dynamic content, the CDN may return controlled error responses rather than overwhelming the origin with retries.
Explaining stale-while-revalidate or serve-stale strategies shows depth in reliability design.
Control plane redundancy and safe operation
The control plane must be highly available and replicated across regions. However, the data plane should continue serving traffic even if parts of the control plane are degraded. Configuration updates should be versioned and applied atomically to avoid partial or inconsistent behavior.
In interviews, emphasizing the separation of control plane failures from data plane serving is critical.
Disaster recovery and extreme scenarios
For extreme failures such as global configuration errors or widespread outages, the CDN should support rollback mechanisms, kill switches, and emergency traffic steering. Operators should be able to revert to known-good configurations quickly.
Discussing disaster recovery signals that you think beyond normal failure modes.
Metrics, observability, and interview wrap-up with trade-offs
Observability is essential for operating a CDN at scale. Key metrics include cache hit ratio, origin fetch rate, latency percentiles, error rates, and PoP saturation levels. These metrics must be collected at high resolution and aggregated across regions.
In interviews, it is valuable to explain how metrics guide both operational response and long-term capacity planning.
Tracing, logging, and debugging at scale
Debugging CDN issues is challenging because traffic is distributed and failures may be localized. Distributed tracing, structured logs, and request sampling help operators understand end-to-end behavior without overwhelming storage systems.
Explaining how observability tools are designed to scale shows practical experience.
Alerting and automated responses
Alerts should focus on user-visible impact rather than internal noise. Automated responses, such as traffic shifting or cache policy adjustments, can reduce mean time to recovery. However, automation must be carefully bounded to avoid runaway behavior.
Interviewers often appreciate a nuanced discussion of automation risks.
Key trade-offs to articulate in interviews
CDN design involves constant trade-offs. Lower latency often increases cost. Strong consistency reduces availability. Aggressive caching improves performance but risks staleness. More edge logic increases flexibility but expands the attack surface.
Explicitly calling out these trade-offs demonstrates senior-level System Design thinking.
How to present this design under time pressure
In a time-limited interview, prioritize explaining routing, caching, and failure handling. These areas best demonstrate distributed systems expertise. Avoid spending too much time on UI or vendor-specific features unless prompted.
Showing that you can adapt depth based on time constraints is itself an interview skill.
Using structured prep resources effectively
Use Grokking the System Design Interview on Educative to learn curated patterns and practice full System Design problems step by step. It’s one of the most effective resources for building repeatable System Design intuition.
You can also choose the best System Design study material based on your experience:
Final thoughts
Designing a CDN System Design is about more than caching content close to users. It is about building a globally distributed platform that balances latency, availability, cost, and security under constant change and failure. Interviewers use CDN questions to assess whether you can reason about systems at internet scale.
Strong answers focus on fundamentals: request routing, cache hierarchy, freshness, and failure handling. They explicitly acknowledge trade-offs and justify design choices based on real-world constraints. If you approach the problem methodically and communicate clearly, CDN System Design becomes an opportunity to showcase deep systems thinking rather than a memorization exercise.
